
Please read Part 1 here.
Roadmap
When we launch a series of PoCs (ideally, it is a constant process) and define what data we need, we must consider where we will get data if we implement ML in production. We also need to look at the data we have internally and how we can use it to our advantage.
This is another crucial point where things might go wrong. Often, a company will rely on supervised learning PoC, which uses a well-prepared dataset containing 10-50 thousand data points. In reality, they barely have a few thousand good-quality data points.
There are a few possible ways to solve this problem (and we often end up using a combination of them):
Use unlabeled data available with the help of:
- weak supervision,
- semi-supervised techniques,
- active learning.
Or generate data from the data we have using the same techniques above.
Below is a simplified representation of the process:
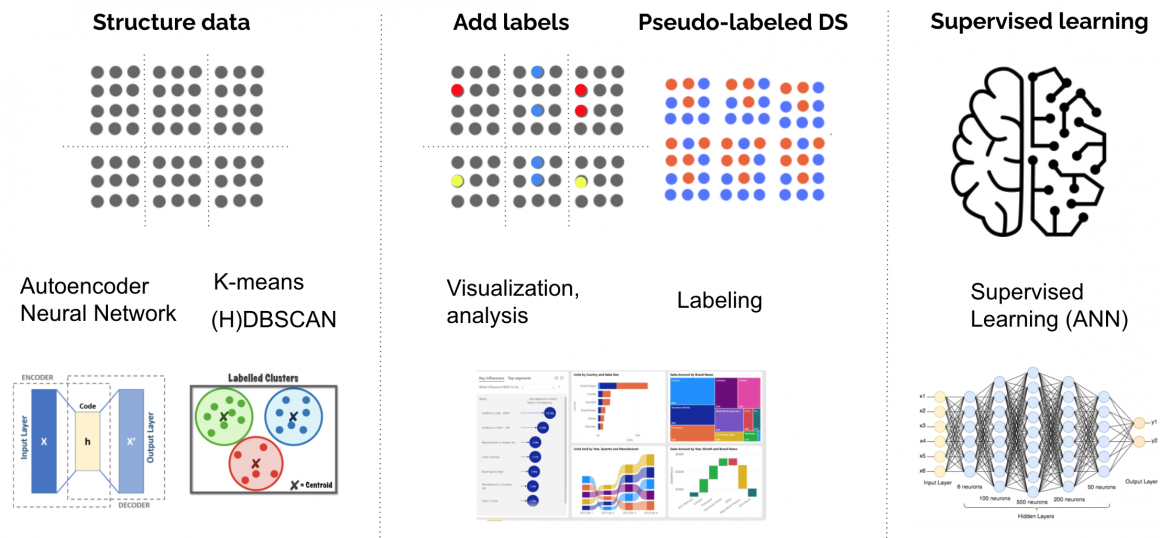


It is often the case that we do not have a vast amount of good-quality data. But it shouldn’t prevent us from rolling out solutions. Quite the opposite.
We can roll out the solution to gather the data from real users or the real world and improve the model(s).
Now you have methodologies, tech, and models (requiring improvement) and you have defined your strategy for acquiring the necessary data, there are a few more things you have to think about:
How you will deploy and serve your models. This will require developing and combining many pieces of software and infrastructure in a streamlined process.
How you will deal with disrupting factors, such as:
- Inconsistent and corrupted data,
- Security breaches,
- Software failure,
- Environment failure,
- People mistakes.
There is a difference between setting up training and serving pipelines for your models.
Training a production-grade model requires Data Transformation and Ingestion Pipelines split across a fleet of machines. Ideally, the training process should also be divided across a pool of non-unique resources. When training is done, there is usually a pause until the data schema or something else is changed. The next training iteration is planned and prepared beforehand.
This is different from the inference part because it has a semi-unpredictable nature of the load during model serving. So, when we plan implementation, we should account for such specificity and design an elastic or serverless pool of resources that serve the inference phase in production.
When you consider all the factors above, you should get a comprehensive set of programs in the spheres of:
- Implementing and improving models,
- Implementing Data Strategy required for models to train and improve,
- Implementing the necessary infrastructure and software to train and serve production ML.
Based on the priority of Automation Points to which each program belongs and estimations, you can build the Roadmap and calculate implementation Budgets.
Monitor and Improve
One more critical point worth a separate section – Monitoring and Improving.
First, we should decide on a set of metrics that represent the health and quality of our system.
In general, metrics could measure the performance of:
- Infrastructure.
- Software.
- Security.
- Model inputs (data ingest).
- Model outputs.
- User behavior.
Ways of measuring infrastructure, software, and security metrics are vast and well-documented, so we will not stop on them. Apart from these, we should measure and validate the data that we use to train our model and the data that the model works with during the inference. Data is changing and is not static. As a bare minimum, we can measure Data Statistics and Data Schema. In other articles, I’ll show how to establish a system measuring and validating ingested data in production.
Improvement areas to focus on are:
- Data preparation pipeline.
- Model architecture.
- Scalability, reliability.
- Security.
One crucial point is that monitoring data and models should have an appropriate horizon. Probably, we don’t want to measure it every minute. Measuring data and model performance every 2-3 years might also not make sense. The appropriate measurement span depends on the specificity of your market and business model. The general recommendation would be to measure inference data on a weekly/monthly basis, Model performance in each inference, and aggregate weekly/monthly data points. However, this is way too general and should be defined based on specific cases.
Conclusion
In this article, we’ve discussed a helicopter view of designing and implementing an AI strategy. It is essential to understand that this process is highly iterative and based on a trial-error loop. Looking at the Roadmap chart above, you will see multiple arrows going back, not just forward.
Last but not least, we should also consider Change Management a crucial part of Digital Transformation (which AI implementation often is). As we change how our business operates, we should manage changes appropriately for this endeavor to be successful. Again, more on this topic will be discussed in further articles.
Thank you for reading this material, and I always appreciate your comments and feedback.

