
This article is part of a series describing Production ML – Production ML Series of Articles.
Training overview
In the previous article (Production ML Data Transformation Pipeline with Apache Beam. Structured Dataset.), we created a data transformation pipeline with the help of Tensorflow Transform library and Apache Beam.
The pipeline transformed our training and testing datasets and saved them to storage. But not just that. It also created a special model which can perform the same data transformation when we perform the inference (when we ask the model to make a prediction).
In this article, we will create a few helper functions, including:
- the function that produces a data generator for the model training,
- the function that produces a data generator for serving the prediction,
- the function that prepares and saves the trained model so it can be deployed later.
These functions above will help us ramp up the training cycle of a simple DNN (Deep Neural Network) model consisting of five hidden layers. We will evaluate its accuracy and save the trained model for further deployment when training is done.
Ok, let’s begin!
Helper functions
We imported all required libraries when building a data transformation pipeline (Production ML Data Transformation Pipeline with Apache Beam. Structured Dataset.), and we will jump straight to helper functions.
First of all, lets set some variables we will be using later:
#train model for 25 epochs
TRAIN_NUM_EPOCHS = 25
#set the number of train datapoints
#we will use it to calculate number of steps per epoch
NUM_TRAIN_INSTANCES = 32561
#set batch size (not too small)
TRAIN_BATCH_SIZE = 128
#set the number of train datapoints
#we will use it to calculate number of steps per epoch
NUM_TEST_INSTANCES = 16281
#define folders with transformed data
TRANSFORMED_TRAIN_DATA_FILEBASE = 'train_transformed'
TRANSFORMED_TEST_DATA_FILEBASE = 'test_transformed'
#set folder for model export
EXPORTED_MODEL_DIR = 'exported_model_dir'
#set data specification
RAW_DATA_FEATURE_SPEC = dict(
[(name, tf.io.FixedLenFeature([], tf.string))
for name in CATEGORICAL_FEATURE_KEYS] +
[(name, tf.io.FixedLenFeature([], tf.float32))
for name in NUMERIC_FEATURE_KEYS] +
[(name, tf.io.VarLenFeature(tf.float32))
for name in OPTIONAL_NUMERIC_FEATURE_KEYS] +
[(LABEL_KEY, tf.io.FixedLenFeature([], tf.string))]
#and don't forget the labels
LABEL_KEYS_TABLE = ['>50K', '<=50K']And create a generator function that will accept TFTransformOutput object (containing information about transformed data), datapoints and batch size. The function will return another function which will return the TF Dataset object created from Example protos. It doesn’t sound straightforward, so let me explain in plain English: it takes data from TFX TFT format and transforms it to TF Dataset, which can be ingested in the model during training.
def _make_training_input_fn(tf_transform_output, transformed_examples, batch_size):
def input_fn():
return tf.data.experimental.make_batched_features_dataset(
file_pattern=transformed_examples,
batch_size=batch_size,
features=tf_transform_output.transformed_feature_spec(),
reader=tf.data.TFRecordDataset,
label_key=LABEL_KEY,
shuffle=True
).prefetch(tf.data.experimental.AUTOTUNE)
return input_fnThe helper function that works with serving data will be a bit wordier. It accepts the same inputs and produces a serving input data generator. However, internally this function will be a bit more complicated because serving inputs will require data transformation to be made.
def _make_serving_input_fn(tf_transform_output, raw_examples, batch_size):
#generate default values for features in dataset
def get_raw_data_defaults():
result = []
for col in ORDERED_CSV_COLUMNS:
#set 0.0 for all features that we don't care about
if col not in RAW_DATA_FEATURE_SPEC:
result.append(0.0)
continue
#get feature specification
spec = RAW_DATA_FEATURE_SPEC
#categorical features are all fixedlenfeature so we lookup the dtype
if isinstance(spec, tf.io.FixedLenFeature):
result.append(spec.dtype)
else:
#and if not fixedlenfeature means that its numerical feature, set to 0.0
result.append(0.0)
return result
#function that will return dataset generator
def input_fn():
#initiate data generator
dataset = tf.data.experimental.make_csv_dataset(
file_pattern=raw_examples,
batch_size=batch_size,
column_names=ORDERED_CSV_COLUMNS,
column_defaults=get_raw_data_defaults(),
prefetch_buffer_size=0,
ignore_errors=True
)
#initiate model/layer that will perform data transformation
tft_layer = tf_transform_output.transform_features_layer()
#transformation function
def transform_dataset(data):
raw_features = {}
for key, val in data.items():
#skip if feature is not in feature specification
if key not in RAW_DATA_FEATURE_SPEC:
continue
#transform sparse feature values to sparse tensor
if isinstance(RAW_DATA_FEATURE_SPEC[key], tf.io.VarLenFeature):
raw_features[key] = tf.RaggedTensor.from_tensor( tf.expand_dims(val, -1)).to_sparse()
continue
raw_features[key] = val
#run same data transformation that was performed for train data
transformed_features = tft_layer(raw_features)
#remove labels
data_labels = transformed_features.pop(LABEL_KEY)
return (transformed_features, data_labels)
#run transformation function for each datapoint in dataset
return dataset.map( transform_dataset,
num_parallel_calls = tf.data.experimental.AUTOTUNE
).prefetch(tf.data.experimental.AUTOTUNE)
return input_fnLast but not least, we will prepare our model for deployment. The function below will receive theTFTransformOutput object, model, and folder name where we expect it to save the exported model.
def export_serving_model(tf_transform_output, model, output_dir):
#add data transformation layer to the model
model.tft_layer = tf_transform_output.transform_features_layer()
#model is wraped with serving function
#serving function is saved as a graph
#tf.function works best with TensorFlow ops; NumPy and Python calls are converted to constants.
@tf.function
def serve_tf_examples_fn(serialized_tf_examples):
#
feature_spec = RAW_DATA_FEATURE_SPEC.copy()
feature_spec.pop(LABEL_KEY)
parsed_features = tf.io.parse_example(serialized_tf_examples, feature_spec)
transformed_features = model.tft_layer(parsed_features)
outputs = model(transformed_features)
classes_names = tf.constant([['0', '1']])
classes = tf.tile(classes_names, [tf.shape(outputs)[0], 1])
return {'classes': classes, 'scores': outputs}
concrete_serving_fn = serve_tf_examples_fn.get_concrete_function(tf.TensorSpec(
shape=[None],
dtype=tf.string,
name='inputs'
))
signatures = {'serving_default': concrete_serving_fn}
versioned_output_dir = os.path.join(output_dir, '1')
#save the model
model.save(versioned_output_dir, save_format='tf', signatures=signatures)
In the code above, we transform the serving function to the graph. The graph mode speeds up calculation because it creates Python independent data flow graph where, whenever possible, Python calls are turned into constants. You can read more at https://www.tensorflow.org/guide/function.
Now we will make it all work together as a cohesive whole. The function below accepts the working directory name as a parameter and the number of test and train instances for parallel computation. With these parameters function:
- loads transformed in previous steps data,
- defines the model,
- perform training of the model,
- evaluate and export model.
Ok, let’s take a close look now.
def train_and_evaluate(working_dir,
num_train_instances=NUM_TRAIN_INSTANCES,
num_test_instances=NUM_TEST_INSTANCES):
#define train and test data path
train_data_path_pattern = os.path.join( working_dir, TRANSFORMED_TRAIN_DATA_FILEBASE + '*')
eval_data_path_pattern = os.path.join( working_dir, TRANSFORMED_TEST_DATA_FILEBASE + '*')
#load transformed data
tf_transform_output = tft.TFTransformOutput(working_dir)
#initialize training dataset generator
train_input_fn = _make_training_input_fn( tf_transform_output,
train_data_path_pattern,
batch_size = TRAIN_BATCH_SIZE)
#load train data
traind_dataset = train_input_fn() ##
#initialize evaluation dataset generator
eval_input_fn = _make_training_input_fn( tf_transform_output,
eval_data_path_pattern,
batch_size = TRAIN_BATCH_SIZE)
#load data for evaluation
eval_dataset = eval_input_fn() ##
#load feature spec
feature_spec = tf_transform_output.transformed_feature_spec().copy()
feature_spec.pop(LABEL_KEY) ##
#prepare model input layers
inputs = {}
for key, val in feature_spec.items():
if isinstance(val, tf.io.VarLenFeature):
inputs[key] = tf.keras.layers.Input( shape=[None], name=key, dtype=val.dtype, sparse=True)
elif isinstance(val, tf.io.FixedLenFeature):
inputs[key] = tf.keras.layers.Input( shape=val.shape, name=key, dtype=val.dtype)
else:
raise ValueError('Feature data type is not supported: ', key, val)
encoded_inputs = {} #
for key in inputs:
feature = tf.expand_dims(inputs[key], -1)
if key in CATEGORICAL_FEATURE_KEYS:
num_buckets = tf_transform_output.num_buckets_for_transformed_feature(key)
encoding_layer = (tf.keras.layers.experimental.preprocessing.CategoryEncoding(
num_tokens=num_buckets,
output_mode='binary', sparse=False))
encoded_inputs[key] = encoding_layer(feature)
else:
encoded_inputs[key] = feature
#model architecture including concatenated input layers
stacked_inputs = tf.concat(tf.nest.flatten(encoded_inputs), axis=1)
output = tf.keras.layers.Dense(100, activation='relu')(stacked_inputs)
output = tf.keras.layers.Dense(70, activation='relu')(output)
output = tf.keras.layers.Dense(50, activation='relu')(output)
output = tf.keras.layers.Dense(20, activation='relu')(output)
output = tf.keras.layers.Dense(2, activation='sigmoid')(output)
model = tf.keras.Model(inputs=inputs, outputs=output)
#initialize
model.compile(optimizer='Adam',
loss='binary_crossentropy',
metrics=['accuracy', ])
#train model
model.fit(traind_dataset,
validation_data=eval_dataset,
epochs=TRAIN_NUM_EPOCHS,
steps_per_epoch=math.ceil(num_train_instances / TRAIN_BATCH_SIZE),
validation_steps=math.ceil(num_test_instances / TRAIN_BATCH_SIZE))
#export model
exported_model_dir = os.path.join(working_dir, EXPORTED_MODEL_DIR) #
export_serving_model(tf_transform_output, model, exported_model_dir)
#evaluate model
metric_values = model.evaluate(eval_dataset, steps=num_test_instances)
metric_labels = model.metrics_names
#return model evaluation results
return {label: val for label, val in zip(metric_labels, metric_values)}We have everything necessary to train our model on the dataset we’ve prepared.
import tempfile
temp = os.path.join(tempfile.gettempdir(), 'keras')
results = train_and_evaluate(temp)
pprint.pprint(results)After running the cell above, colab (or your local/cloud environment) will train the model for 25 epochs, evaluate it, and export it for deployment. You should see results similar to below:
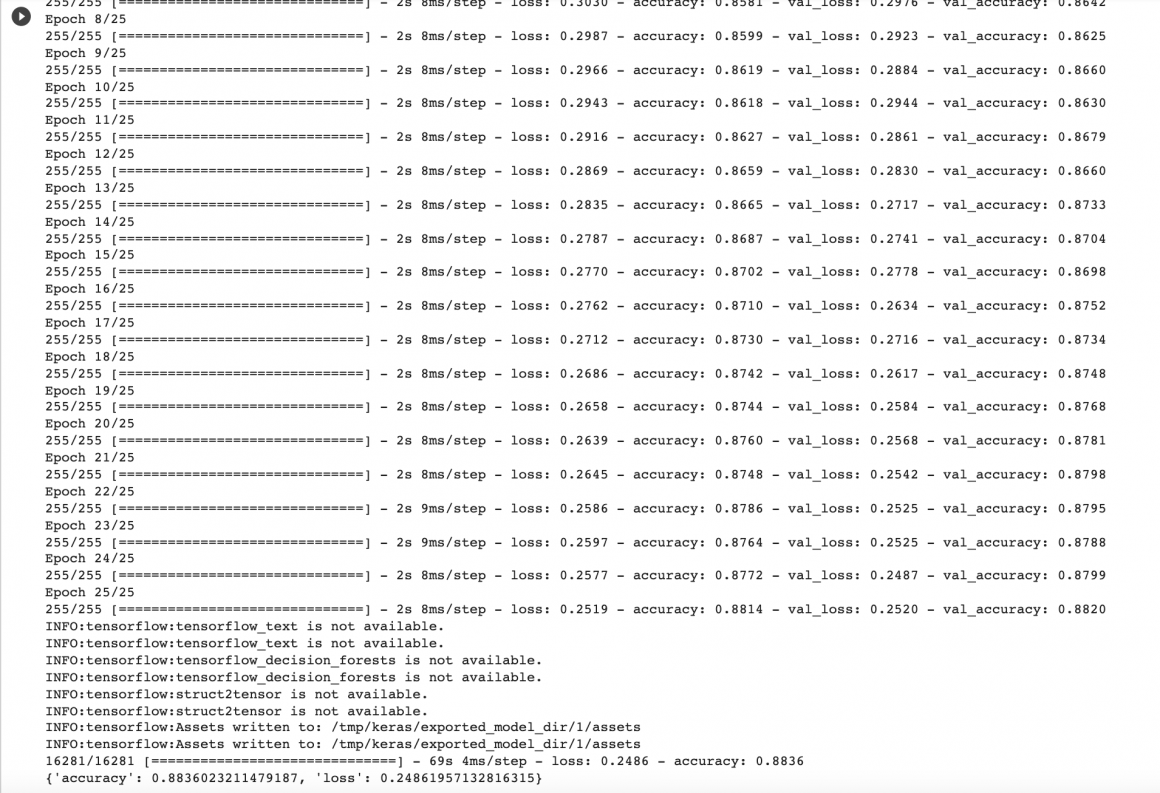
In just 25 epochs, we managed to get decent 88% evaluation accuracy, which is not bad.
You can see the exported model in the ‘tmp/keras/exported_model_dir/1/’ folder.
Conclusion
This article demonstrated how to load the data transformed with TFX and train the model. Hopefully, it all makes sense to you because you saw an almost complete cycle.
I said almost because, in further articles, we will see how to deploy and serve models in production-grade systems. We will also talk about hyperparameters tuning and Neural Architecture Search, which will help us find the best architecture and set-up for our solution.
Thank you for reading, and I hope you will find the materials you read today helpful.
