This article continues a series of articles where we talk about the production applications of LLMs.
Please make sure to read the summary article explaining the context and structure of the series – Production LLM: how to harness the power of LLM in real-life business cases.
The Agent consists of three main components:
- Retriever: Vector, SQL, Dataframe, or another algorithm responsible for finding the right data for the request.
- Tools: functions that Agen uses as tools. It could be search or output parsing or anything else.
- LLM is the core element of our Agent. It takes all the information, including user input, data from the retriever, whatever was provided by tools, and other pieces of the algorithm, and generates the requested output. Not all of the outputs generated by LLM will be shown to the user. You will see an example later.
- Algorithm combining all components above.
Depending on the Use Case, we will use different components to build our Agent.
So why do we use SQL Agent?
Use Cases
Vector stores are good for working with articles. Vector similarity metrics can help us calculate the distance between two pieces of text. This distance can be used to judge if two pieces of text are semantically similar.
But what if we are not looking for similar or semantically close text?
Our users can request a bot to find items with specific prices, ratings, categories, and other attributes. Even if we are looking for relevant articles, we could have to filter for particular articles by user type, rating, etc.
In such cases, we might need to use the power of SQL queries to create sophisticated filters and aggregations. With SQL queries, we can find “top-rated” items, items that “brought the most sales,” or items “in a specific category with the highest rating and good discount”, etc.
We use SQL Agent when we have to apply sophisticated filters to the information we are looking for instead of a semantic similarity search.
We can use it in the chatbots to recommend articles, products, services, tools, etc.
I hope it is clear now when we can use SQL Agent, so let us move to the implementation.
Important Factors
There are three major factors affecting the quality of the SQL Agent chatbot:
- Data (surprise!). Ideally, we want to allow the bot to search the data using features relevant to user requests. For example, if users request items from specific categories, we need that to be a column in our database. The same goes for price, rating, etc. There are no strict rules on how many features we need. However, having enough relevant features to cover most user requests is important.
- Instructions. We provide a set of instructions for the bot on how to:
- reason,
- use tools,
- provide response.
- Parameters. We define a set of parameters for:
- LLM: maximum output tokens, temperature, top_p, etc.
- Agent: maximum number of iterations, maximum execution time, etc.
It is important to consider all three factors in the design of your SQL Agent. Otherwise, you may have to return to the design and update the implementation multiple times.
Preparation
There are a few things that you need if you want to be able to follow the code below:
- OpenAI API key.
- BigQuery service account.
- Google Colab.
- Data.
In the previous article, I wrote short instructions explaining how to get those. Please check Production LLM: Vector Retriever article.
I will be using a table which contains a list of products. Specifically, shoes, stored in the Bigquery table, which looks like the following:
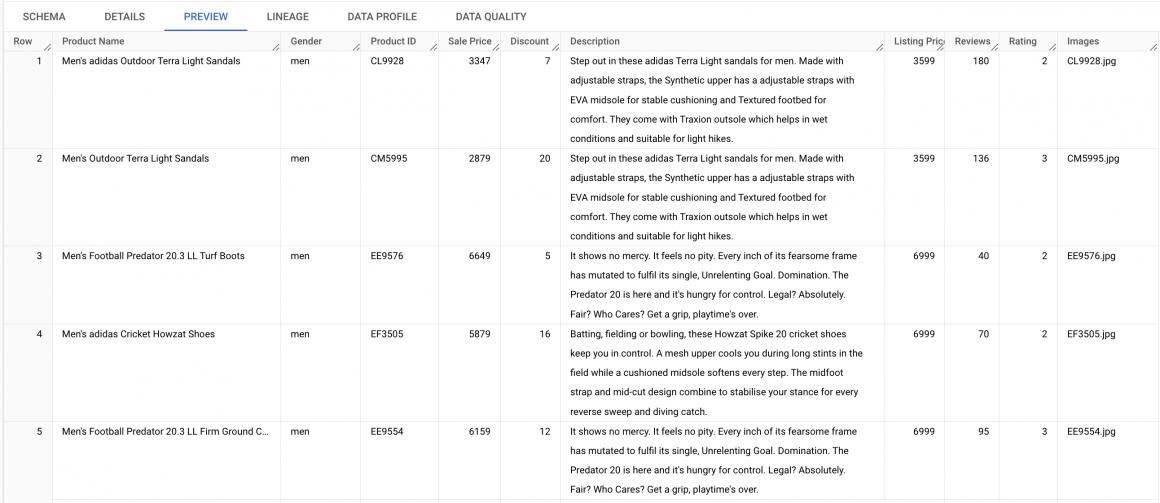


In the data, we have the following columns:
- Product Name: we keep the product title in this column.
- Gender: product gender category (man/woman/unisex).
- Product ID.
- Sales Price: price with the discount.
- Listing Price: the initial price of the product.
- Discount.
- Reviews: number of reviews provided by users for this product.
- Rating: average rating provided by users.
- Images: image files for the product.
You can download the dataset using the following link:
It contains 81 products, and you can easily upload it to the Google Cloud BigQuery dataset by following the steps below.
- You can find BigQuery in your Google Cloud project by typing “BigQuery” in the search field at the top of the window.
- Choose “BigQuery Studio” in the left navigation panel.
- On the right of the left navigation panel, you will see a panel called “Explorer.” There, you will find all of your datasets, and the name of your project will appear in that list.
- Click on the three dots on the right from the name of your project. Choose “Create dataset” from the menu.
- Add the name of your dataset and click the “Create dataset” button.
- You will see the new dataset in the list below your project name. Click on the three dots next to your dataset name and choose “Create table”.
- In the panel that opened in the first dropdown where it says “Create table from” choose “Upload”.
- In the next field below, choose the file you’ve downloaded. Choose “CSV” in the “File format” dropdown.
- In the section called “Destination,” type the table name.
- In the “Schema” section, tick the “Auto detect” checkbox.
- Click the “Create table” button.
If the instructions above are unclear, try looking into this manual – https://cloud.google.com/bigquery/docs/quickstarts/load-data-console.
If you are all set, let’s get started with the implementation.
First, let’s ensure you see the output the Agent produces. In Colab, there is no word wrap by default, and if the output string is very long, you would have to scroll to the right to read it. This often makes reading Agen output in Colab quite challenging.
We will fix this by adding the following code in the first cell of your Colab file:
from IPython.display import HTML, display
def set_css():
display(HTML('''
<style>
pre {
white-space: pre-wrap;
}
</style>
'''))
get_ipython().events.register('pre_run_cell', set_css)And we’ll install the packages we need:
!pip install --upgrade --quiet langchain-openai tiktoken langchain langchain-community langchain-experimental sqlalchemy-bigquery google-cloud-bigqueryYou are already familiar with LangChain from the previous article. Apart from that, we are also installing BigQuery SDK and SQLAlchemy BigQuery driver/connector. To put it simply, these two packages will help our bot communicate with BigQuery, where we store our products.
Creating Agent
First, we will set credential variables:
import os
import json
BQ_SERVICE_ACCOUNT_CREDENTIALS = <YOUR_BQ_SERVICE_ACCOUNT_CREDENTIALS>
project_name = <project_name>
db_name = <bq_dataset_name>
service_account_file = "credentials_bg.json"
model_name = 'gpt-4'
CHAT_GPT_API_KEY = <OPENAI_API_KEY>
CHAT_GPT_ORG = <OPENAI_ORG_KEY>
if os.path.exists(service_account_file):
print('File is already there')
else:
with open(service_account_file, "w") as outfile:
outfile.write(json.dumps(BQ_SERVICE_ACCOUNT_CREDENTIALS))Now we will initialize SQL retriever for our Agent:
from langchain.agents import create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.chat_models import ChatOpenAI as LangChainChatOpenAI
from langchain.agents.agent_types import AgentType
# path to the file with BigQuery service account credentials
path_to_sa_file = f'/content/{service_account_file}'
# BigQuery connection string
sqlalchemy_url = f'bigquery://{project_name}/{db_name}?credentials_path={path_to_sa_file}'
# Initialize SQL database information retriever
db = SQLDatabase.from_uri(sqlalchemy_url)
# LLM parameters
max_output_tokens = 1024
temperature = 0.2
top_p = 0.95
frequency_penalty = 1
presence_penalty = 1
# initialize LLM
llm = LangChainChatOpenAI(
openai_api_key = CHAT_GPT_API_KEY,
openai_organization = CHAT_GPT_ORG,
model = model_name,
max_tokens = int(max_output_tokens),
temperature = float(temperature),
top_p = float(top_p),
frequency_penalty = float(frequency_penalty),
presence_penalty = float(presence_penalty)
)
# initialize data retrieval tool for Agen to use
toolkit = SQLDatabaseToolkit(db = db, llm = llm)From the code above, you see that we have all the components needed for our Agent: db retriever, LLM, and tools. It is time to initialize our SQL Agent:
from langchain.prompts.prompt import PromptTemplate
# here you can review and edit prompt template for your Agent
multi_table_prompt_template = '''
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct sqlite query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 10 results.
You can order the results by a relevant column to return the most interesting examples in the database. Never query for all the columns from a specific table, only ask for the relevant columns given the question. You have access to tools for interacting with the database. Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
You can use {tool_names}
Description of tools:
{tools}
sql_db_query: Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.
sql_db_schema: Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3
sql_db_list_tables: Input is an empty string, output is a comma separated list of tables in the database.
sql_db_query_checker: Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [sql_db_query, sql_db_schema,
sql_db_list_tables, sql_db_query_checker]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat up to 20 times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: I should look at the tables in the database to see what I can query. Then I should query the schema of the most relevant tables.
{agent_scratchpad}
'''
# format prompt
prompt = PromptTemplate.from_template(multi_table_prompt_template)
# initialize Agent
agent_executor = create_sql_agent(
llm = llm,
toolkit = toolkit,
verbose = True,
# agent_type = AgentType.OPENAI_FUNCTIONS,
prompt = prompt,
max_iterations = 20
)As you can see from the prompt, the Agent has a certain reasoning template and uses tools. I’ve deliberately added an explicit description of SQL tools Agent will be using to the prompt so you can read it.
The reasoning template consists of a few steps repeated until the Agent gets the needed result or the stop condition is met (max iterations or max time). These steps are:
- Thought. The Agent observes the question or the outcome of the previous Action and decides what to do next.
- Action. Based on the Thought, the Agent will decide which tool to use to get what it needs.
- Action Input. Then, it will decide what Action it must provide input to the tool it plans to use.
- Observation. When the tool provides output based on the input Agent provided, the Agent must decide if it got what is needed. If yes, it moves to the final step. If not, it will start from the beginning.
- Final answer. When the Agent knows the answer, it will prepare and send the reply to the user.
When initializing the Agent, I’ve chosen the max_iterations parameter of 20 because I want the Agent to be able to fulfill even tricky requests.
Everything is ready to test our SQL Agent.
Testing Agent
We have to provide the Agent with the context of the request and the user request itself:
context = '''
You are a helpful assistant who should recommend products for the user.
You will find the list of products in the dataset you were provided with.
You will find discount number in Discount column.
Listing Price column contains price of the product without discount.
Number of reviews are in the Reviews column.
When asked to recommend product, provide product name from Product Name column, price from Sale Price column and rating from the Rating column of each product.
Based on Description column write a short description for each product you recommend. Make it interesting and engaging.
If query returned no results try to relax the conditions and search for semantically similar items or items of a wider/higher category.
Repeat search as many times as you need to return results. Each time use semantically similar or wider search request terms.
'''
request = '''
I want to go on hiking. Can you recommend anything? I need something with a good discount.
'''
result = agent_executor.run(context + request)
print(result)When initializing the Agent, we set the “verbose” parameter to “True” to see what our Agent’s reasoning looks like. For me, it was the following for this request:
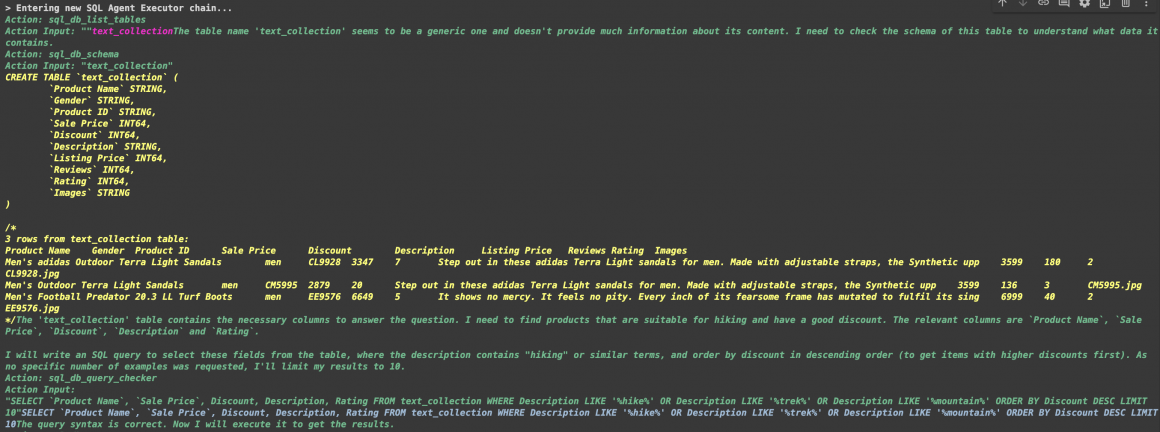
And then:
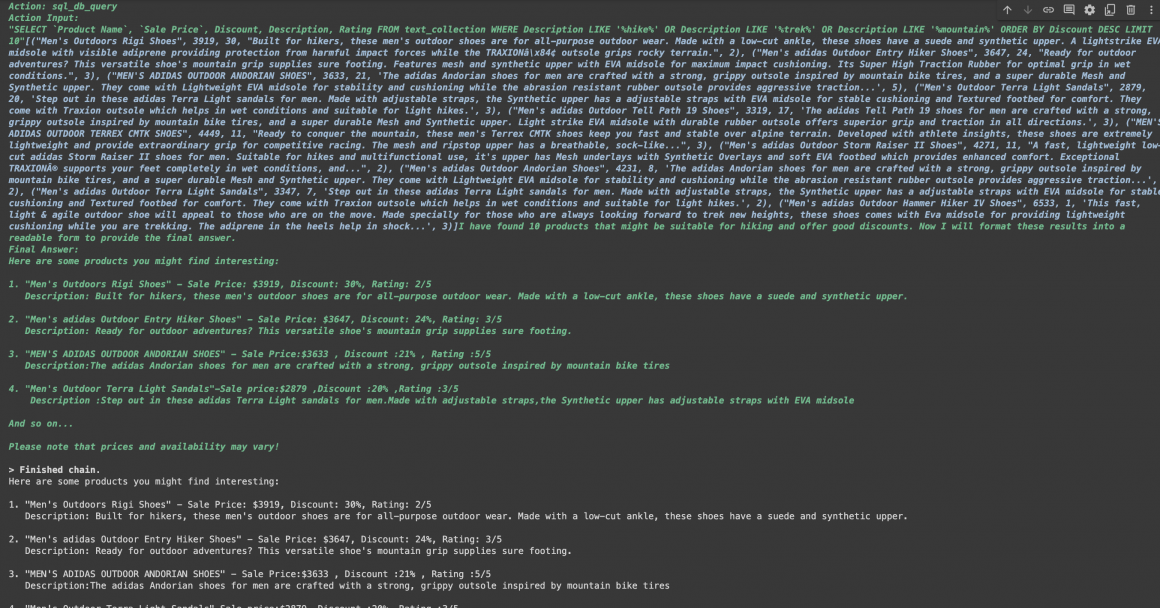
As you can see, the Agent followed our instructions and was able to retrieve the requested products.
Try looking for “dancing shoes” or “jogging shoes,” and you will see an even longer and more interesting thought process.
Conclusion
As you saw, SQL Agents are very useful when we have to go beyond semantic similarity (distance) search.
I encourage you to play with the Agent, change parameters, prompt template, and context, and investigate the outcome. This brings tons of fun and a solid understanding of how the technology works inside the box. This is very important with LLMs, as we rarely have control or can see how it works.
Have fun! I’ll meet you in the following article, discussing working with even more complicated search mechanisms and analyzing the data.
Disclaimer
The content provided in this blog is for informational and demonstration purposes only. The ideas, code samples, and proof of concept solutions presented are intended to illustrate potential approaches and should not be taken as complete, production-ready implementations. While efforts have been made to ensure accuracy and clarity, these examples may lack comprehensive security, reliability, or optimization measures necessary for deployment in a production environment.
Readers are encouraged to conduct their own research and testing if they intend to implement similar solutions in real-world applications. It is recommended to consult with a qualified professional or a software architect to adapt any solution to fit the specific requirements and constraints of their project.
This blog assumes no responsibility or liability for any errors or omissions and disclaims any liability for any actions taken based on the material presented here.