A couple of days ago, I realized that most of the articles are focused on the ML part of the work. And there is not enough material on data engineering and pipelines.
In this series of articles, we will focus on Big Data pipelines and on righting this injustice.
Big Data pipelines, in a nutshell, are just transportation systems that bring data from their sources closer to the places where they are consumed. Because it brings data closer to the areas of its consumption, sometimes we want pipelines to prepare data and transform it into a format suitable for consumption.
This transformation is usually about turning Data into Information. This phase can include everything from changing data format and schema to feature engineering.
Here, I was going to put a fancy image showing a general data pipeline…
But then I realized that it would not be different from dozens of other websites where I am sure you have already seen this general schema or even drawing showing the data pipeline.
Instead, I decided that we should take a semi-real-word scenario and get our hands dirty. This way, the content should help you get practical hands-on experience that you can use to build your production-grade data pipelines.
Business case
Let’s imagine that we are a big e-commerce company that sells our products online. We have hundreds of thousands of users visiting our website every week to find what they need and make the purchase.
We were using Google Analytics for a while, but now we realize this is no longer what we need. Due to increasing competition, Google Analytics (GA4) capabilities are insufficient today. The company needs to implement advanced analytics, prediction, and recommendation models.
The management of the company made a series of strategic decisions:
company will implement its own tracking of user engagement on the website,
all data about user engagement must be stored in a company Data Warehouse (Big Query),
marketing department will use Looker Studio as a primary BI tool to analyze user behavior.
And it is time for us (Data Team) to do our part, which is:
- Implement real-time processing of the events from the website and mobile app (stream processing).
- Migrate old data that we have in the GA4 because the marketing team needs this data for analysis, predictions, and recommendations.
There is a point in time (a day) from which data will start flowing from the company’s own tracking solution. After this point in time, all user engagement data will come through the streaming pipeline.
GA4 tracking will be switched off after this point in time. And the historical data must be migrated from GA4 to the company DW.
Requirements
Sounds great, right? Finally, we get to do a real job!
Functional requirements
As usual, there are only general requirements; many details are missing. Data is stored and comes in the form of events, which look like the following JSON:
{
"event_date": "20210131",
"event_timestamp": "1612069510766593",
"event_name": "page_view",
"event_params": [{
"key": "gclid",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "gclsrc",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "debug_mode",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "ga_session_number",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "all_data",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "page_location",
"value": {
"string_value": "https://shop.googlemerchandisestore.com/",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "entrances",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "session_engaged",
"value": {
"string_value": "0",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "ga_session_id",
"value": {
"string_value": null,
"int_value": "661084800",
"float_value": null,
"double_value": null
}
}, {
"key": "clean_event",
"value": {
"string_value": "gtm.js",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "engaged_session_event",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "page_title",
"value": {
"string_value": "Home",
"int_value": null,
"float_value": null,
"double_value": null
}
}],
"event_previous_timestamp": null,
"event_value_in_usd": null,
"event_bundle_sequence_id": "6595101026",
"event_server_timestamp_offset": null,
"user_id": null,
"user_pseudo_id": "1026454.4271112504",
"privacy_info": {
"analytics_storage": null,
"ads_storage": null,
"uses_transient_token": "No"
},
"user_properties": [],
"user_first_touch_timestamp": "1612069510766593",
"user_ltv": {
"revenue": "0.0",
"currency": "USD"
},
"device": {
"category": "mobile",
"mobile_brand_name": "Apple",
"mobile_model_name": "iPhone",
"mobile_marketing_name": "\u003cOther\u003e",
"mobile_os_hardware_model": null,
"operating_system": "Web",
"operating_system_version": "\u003cOther\u003e",
"vendor_id": null,
"advertising_id": null,
"language": "en-us",
"is_limited_ad_tracking": "No",
"time_zone_offset_seconds": null,
"web_info": {
"browser": "Safari",
"browser_version": "13.1"
}
},
"geo": {
"continent": "Americas",
"sub_continent": "Northern America",
"country": "United States",
"region": "California",
"city": "San Carlos",
"metro": "(not set)"
},
"app_info": null,
"traffic_source": {
"medium": "organic",
"name": "(organic)",
"source": "google"
},
"stream_id": "2100450278",
"platform": "WEB",
"event_dimensions": null,
"ecommerce": {
"total_item_quantity": null,
"purchase_revenue_in_usd": null,
"purchase_revenue": null,
"refund_value_in_usd": null,
"refund_value": null,
"shipping_value_in_usd": null,
"shipping_value": null,
"tax_value_in_usd": null,
"tax_value": null,
"unique_items": null,
"transaction_id": null
},
"items": []
}Events are simple actions that the user is doing on the website. For example, the user has loaded the page, scrolled or added an item to her cart, etc. A combination of event type and event timestamp is unique for each event.
The vast volumes of historical data were exported from GA4 to a temporary Big Query table and must be migrated to the new company’s Digital Marketing Data Warehouse. New events are coming from the new tracking solution deployed to the website. And they must also come to the new Data Warehouse.
The data schema is dictated by GA4. As you can see, it is pretty complicated. The event has a complex structure and has to be flattened before insertion into the DW so that it is possible to run queries and use this data to train prediction and recommendation models.
Non-functional requirements
After we spoke with the stakeholders, we got some more information and finally got access to the temporary table with historical data.
It turned out that we have at least 40 million events stored in our historical data. And our solution must migrate this data to the new Digital Marketing Data Warehouse (DMDW). The new DMDW, of course, is not ready. So we’ve suggested our help in creating it.
Historical data migration must be performed during a two-day freezing period during a calm part of the week at night time in the primary geography. The company can’t afford longer migration.
Also, the new event-tracking solution is ready and in testing. But as it turned out, it has the front-end part (JavaScript code) and a very basic server-side script, which can send event JSON to a particular endpoint. And it looks like we have to implement the logic of data transformation and insertion into the database ourselves.
Well, that does not seem new as well, right?
Last but not least, nobody could tell us how many events would be coming in during the average hour. The only thing that we know is that we usually have around 1 million events coming every month.
Challenges
There are a few challenging points in the requirements we’ve gathered so far:
- Significant volumes of data. In the event stream, data is of a transactional nature. It is coming in huge, constant volumes. Historical data archives can easily have hundreds of GBs in size.
- Complexity of the data. Even though the nature of the event stream data is transactional, there are different types of events; each can have a very different (and often very complex) structure of properties and sub-properties. Data from the event stream cannot be directly used in the analytics and algorithms.
- Historical data is required and, therefore, must be transformed and migrated to the new system. Given the requirement of a maximum of two days to migrate the historical data, this task becomes challenging.
This is not our first rodeo, and we seem to know how to tackle those challenges:
- The timestamp partition of the data speeds up batch migration. Each batch request filter (query) is performed on the partition rather than the entire table.
- During the historical data migration, event properties must be transformed into a flat structure, which can be used in the analytics and the algorithm.
- Data migration must be highly scalable and parallelizable.
Solution
Given the strategy, requirements, and challenges, the solution we’re implemented consists of two parts:
- Batch Processing of historical events, which were collected by Google Analytics 4. This will be an auto-scalable ETL pipeline capable of processing the necessary volumes within a given time period.
- Stream processing of new events that it will be collecting on the websites and mobile app. This must be an auto-scalable streaming pipeline, which will also transform incoming events on the fly.
This will be the first time I will step out of the role. The technological stack and solution I will describe below will be implemented on the Google Cloud Platform. It could have been any other cloud (AWS, Azure, for example). Here, in this case, I preferred GCP for one single reason – Big Query. GA4 has native export to the Big Query. This makes things easy from the IAM standpoint, and because I am lazy, I prefer sticking to the GCP. But it doesn’t mean that GCP is the only and the best option. But it is definitely not the worst, either 🙂 .
Ok, back to our story!
We will use the following technology stack in our solution:
Google Cloud Platform:
- Big Query: highly scalable Data Warehouse with fast and autoscaled query processing and support partitioning;
- Pub/Sub: highly scalable and reliable message broker for event streaming.
- Cloud Functions: a highly scalable serverless cloud service that can process any number of events coming in the event stream in parallel.
Databricks: a unified data and analytics platform that provides auto-scalable Spark clusters for processing big volumes of data.
Looker Studio: a powerful business intelligence (BI) and data visualization tool that provides native connectors to Big Query Data Warehouse.
Architecture
We will develop two solutions (batch and streaming) and will have two architecture descriptions.
Batch processing solution.
The primary goal of the batch processing solution is to migrate historical data from GA4 into the company’s data warehouse.
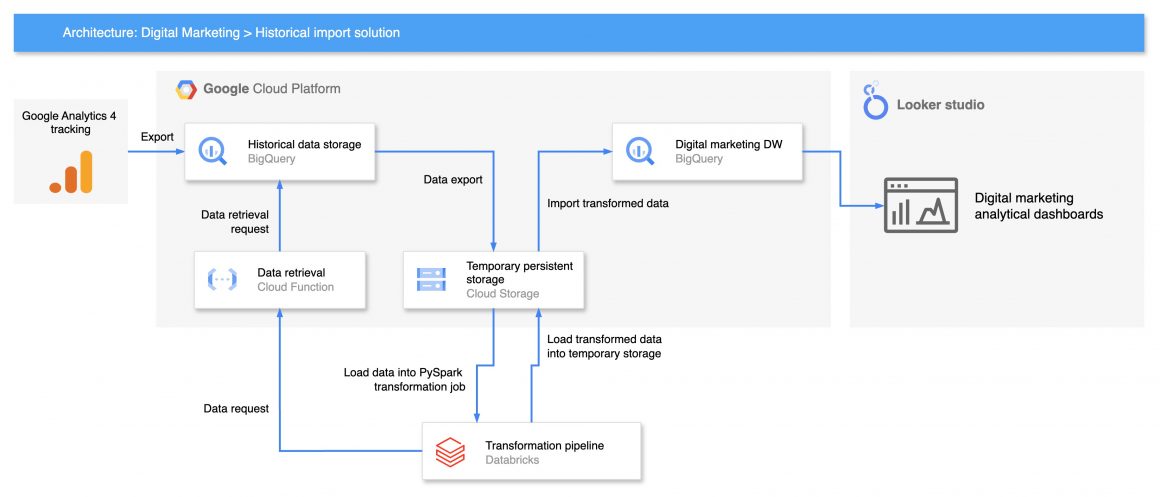


In the first stage, we trigger the export of the data from the GA4 platform into the temporary Big Query table. This transfer is triggered manually in GA4, managed by GA4, and happens on Google Cloud premises.
When the data is in the temporary table, we can trigger batch transfer of the historical data. The batch pipeline consists of a few main elements:
- API-triggered Cloud Function that retrieves data from the temporary Big Query table;
- Cloud Storage bucket storing the intermediary export and import datasets;
- Databricks pipeline orchestrating the flow and transformation of the data;
- Digital marketing Data Warehouse that stores the transformed data.
The primary purpose of having the API-triggered Cloud Function at the beginning of the pipeline is to control the number of rows and sliding windows of the timestamp.
As the volume of data is large, data is migrated to sliding windows using a datetime partition. The time period is the first parameter provided to the Cloud function, so it can filter relevant data using a correct query.
API-triggered Cloud Function is the first stage in the Databricks pipeline. In the next stage, data is exported to Cloud Storage in JSON format.
Next, the pipeline reads the data from cloud storage, initiates the PySpark application, and performs parallel data processing operations in memory.
At this stage, the main purpose of the data processing is to ‘flatten’ the complicated JSON structure of the data and turn it into a tabular format.
When data is transformed, it is saved into the local storage in JSON format. And transferred into the temporary Cloud Storage bucket. In this case, JSONl format is the most lightweight way of storing the data. After the transformation and saving, data takes less space and is ready for the next phase.
The final phase of the pipeline is responsible for importing the data from the temporary Cloud Storage bucket into the Digital Marketing Data Warehouse, where it is ready to be consumed. Exporting from the Cloud Storage bucket is the fastest, most secure, and most scalable way of importing data, in our case.
Stream processing solution.
This solution will be much less complicated. In the first stage, events are coming from the websites and mobile app to the Pub/Sub topic.
Stream processing Cloud Function (CF) is subscribed to the Pub/Sub topic and is notified when the event comes. When an event is received, Cloud Function transforms it and saves it in the Data Warehouse.
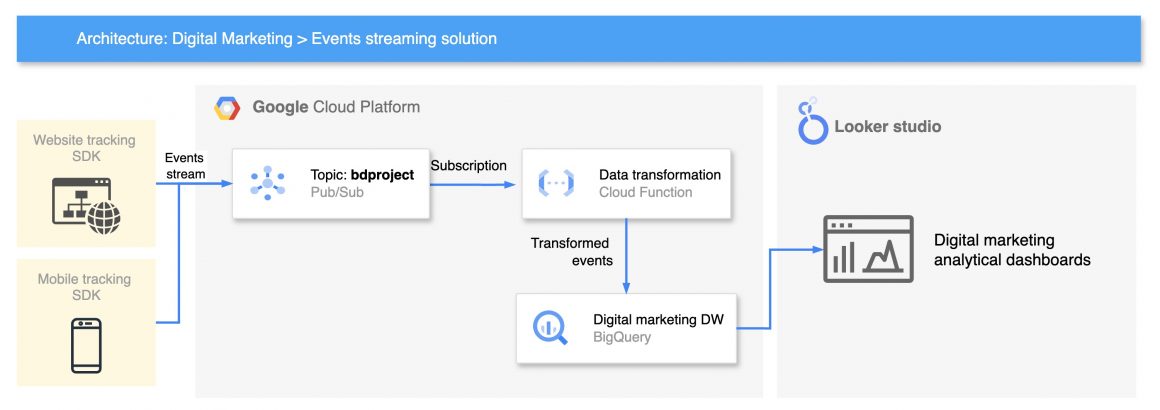
As I said, it’s pretty simple, right?
Implementation steps
In the following few articles, we will implement both solutions step by step.
We will start with the batch-processing solution. After we set up the infrastructure, we will create a data retrieval Cloud Function and the pipeline script.
The data schema of the events in both batch and streaming solutions has a nested structure, which means that we can reuse the same transformation script. We will start implementing the solution from the Pub/Sub topic and continue with the transformation of the Cloud Function.
Lastly, we will connect Loker Studio dashboards to the Digital Marketing Data Warehouse for analytics.
Please continue to the following article, and may the force be with you.
Disclaimer
The content provided in this blog is for informational and demonstration purposes only. The ideas, code samples, and proof of concept solutions presented are intended to illustrate potential approaches and should not be taken as complete, production-ready implementations. While efforts have been made to ensure accuracy and clarity, these examples may lack comprehensive security, reliability, or optimization measures necessary for deployment in a production environment.
Readers are encouraged to conduct their own research and testing if they intend to implement similar solutions in real-world applications. It is recommended to consult with a qualified professional or a software architect to adapt any solution to fit the specific requirements and constraints of their project.
This blog assumes no responsibility or liability for any errors or omissions and disclaims any liability for any actions taken based on the material presented here.