
Key Takeaways
- AI Agents Are Not Perfect: Standard AI agents can misunderstand prompts, hallucinate, or use tools inefficiently. Self-reflection is a powerful technique to address these quality issues (if latency is not an issue).
- The Self-Reflection Loop: This pattern involves an agent generating an initial response, a separate “reflector” model critiquing that response, and the original agent using the feedback to create a superior, revised answer.
- LangGraph is Essential for Implementation: The cyclical, stateful nature of a reflection loop is perfectly suited for LangGraph, which allows developers to build a graph of nodes (actions) and edges (decisions).
- Benefits vs. Costs: While self-reflection significantly improves accuracy, relevance, and reliability, it comes at the cost of increased latency and computational expense due to multiple LLM calls. This trade-off is often worthwhile for critical applications.
Artificial Intelligence (AI) agents are becoming increasingly capable, automating tasks, answering questions, and even generating content. However, like any complex system, they aren’t perfect. AI agent self-reflection is the mechanism that can help them improve.
AI agents can misunderstand prompts, miss nuances, provide inaccurate information (hallucinate), or use their tools inefficiently. So, how do we make them better, more reliable, and more trustworthy?
This article explores the concept of building AI agents that can critique and improve their work, much like a human writer reviews and revises their draft.
We’ll review Python code that implements the “Reflecting Agent” pattern, demonstrating how this capability significantly enhances the quality, accuracy, and relevance of the AI’s output.
Why AI agent self-reflection ?
Imagine asking an AI assistant to research a complex topic. Its first attempt might be okay, but perhaps it missed a crucial perspective, relied on outdated information, or confusingly presented the facts. A standard agent would stop there. A reflecting agent, however, does something different:
- Generates an initial response.
- Critiques its own response: It asks itself questions like “Did I fully answer the user’s question?”, “Is this information accurate and up-to-date?”, “Was my reasoning sound?”, “Did I use the best tools available?”, “Is this clear and easy to understand?”.
- Revises the response based on the critique: It utilizes the insights from its self-critique to generate a more refined and effective answer.
This iterative process leads to:
- Higher Accuracy: Catching factual errors or unsupported claims before they reach the user.
- Improved Relevance: Ensuring the answer directly addresses the user’s specific needs and intent.
- Better Tool Use: Optimizing how the Agent leverages external tools like web search or databases.
- Increased Robustness: Handling ambiguous or complex queries more effectively.
- Enhanced Trust: Users receive more polished, reliable, and thoughtful responses.
This means building more reliable AI-powered products that deliver real value and build user trust. It also signifies a leap towards more dependable AI assistants that require less human oversight. And it represents an advanced technique for pushing the boundaries of agent capabilities.
It’s very cool because it mimics a fundamental aspect of human intelligence – the ability to learn from mistakes and improve.
AI Agent Self-Reflection Technical Implementation
The Agent in this article leverages several powerful frameworks and packages:
- LangChain: Used for structuring the Agent’s workflow, integrating tools, and managing prompts. LangChain offers abstractions that simplify working with language models and enable the development of complex conversational agents.
- LangGraph: Powers the state management and flow control of the Agent. This framework enables the creation of a directed graph that represents the AI Agent’s decision-making process and reflection cycles.
- OpenAI Models: The code utilizes multiple GPT models:
gpt-4.1for the main Agent (high reasoning capabilities)o3-minifor the reflection component (specialized for meta-analysis)gpt-4o-minifor translation tasks (efficient performance)
- External Tools Integration: The Agent can access search engines (Google, DuckDuckGo, Brave), knowledge bases (Wikipedia, Wikidata), and specialized tools (Yahoo Finance).
- Structured Output Parsing: LangChain’s output parsers ensure the AI agent self-reflection follows a consistent format for practical analysis.
This architecture separates concerns effectively: the main Agent handles user queries, while a dedicated reflection component provides critical analysis of responses.
Detailed AI Agent Self-Reflection Code Breakdown
Let’s analyze the key components of this sophisticated self-reflecting Agent:
1. Setup and Configuration
First, we can install the dependencies.
!pip install -q langchain langchain_openai langgraph langchain-core langchain-community langchain-tavily mediawikiapi wikibase-rest-api-client wikipedia duckduckgo-searchAnd import all required packages:
import io
import json
import os
import re
from datetime import datetime
from pathlib import Path
from typing import Any, Literal, List
import requests
from langchain_openai import ChatOpenAI
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain.prompts.chat import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate
from langchain.tools import tool
from langchain_community.tools import (BraveSearch, DuckDuckGoSearchRun,
YahooFinanceNewsTool)
from langchain_community.tools.wikidata.tool import (WikidataAPIWrapper,
WikidataQueryRun)
from langchain_community.tools.wikipedia.tool import WikipediaQueryRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_community.utilities.wikipedia import WikipediaAPIWrapper
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage, ToolMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.tools import Tool
from langchain_tavily import TavilyExtract
from langgraph.graph import END, START, MessagesState, StateGraph
from PIL import Image
from pydantic import BaseModel, Field
from rich.console import Console
from rich.markdown import Markdown
from rich.pretty import pprint
VERBOSE = int(os.getenv("VERBOSE", 1)) == 1
MAX_ITERATIONS = 3
# Setup LLM models
main_agent_model = ChatOpenAI(model="gpt-4.1", temperature=0)
reflection_agent_model = ChatOpenAI(model="o3-mini", reasoning_effort="medium")
translation_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
This section imports necessary libraries and initializes three different language models for specialized tasks:
- The main agent using GPT-4.1 (with temperature=0 for maximum determinism),
- A dedicated reflection model using o3-mini with medium reasoning effort,
- A lightweight translation model using GPT-4o-mini.
Setting MAX_ITERATIONS = 3 ensures the AI agent self-reflection process terminates after a reasonable number of cycles, preventing excessive processing or potential loops.
2. Tool Definition
# Specialized Tools for Agent
@tool(
"retrieve_current_datetime",
return_direct=True,
parse_docstring=True
)
def retrieve_current_datetime() -> str:
"""Retrieve current date and time."""
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Retrieved current time: {current_time}")
return current_time
class TranslationRequest(BaseModel):
"""Data schema for language translation requests."""
text: str
source_language: str
target_language: str
@tool(
"perform_translation",
return_direct=True,
args_schema=TranslationRequest,
parse_docstring=True
)
def perform_translation(text: str, source_language: str, target_language: str) -> str:
"""Translate provided text from source language to target language."""
return translation_model.invoke(
[
("system", f"Translate the following from {source_language} to {target_language}. Return translated sentence only."),
("human", text),
]
).content
class URLFetchRequest(BaseModel):
"""Request schema for fetching content from URLs."""
webpage_url: str = Field(..., description="Mandatory website url to read")
@tool(
"fetch_url_content",
return_direct=True,
args_schema=URLFetchRequest,
parse_docstring=True
)
def fetch_url_content(webpage_url: str) -> str:
"""Fetch and summarize content from a URL."""
extractor = TavilyExtract(extract_depth='basic', include_images=False)
result = extractor.invoke({"urls": [webpage_url]})
print("content_extractor_result: ", result)
return result["results"][0]["raw_content"]
web_search_description = (
"a web-search engine. "
"useful for when you need to answer questions about current events."
" input should be a search query."
)
tools = [
retrieve_current_datetime,
perform_translation,
fetch_url_content,
YahooFinanceNewsTool(),
Tool(
name="Web_search_Google",
func=GoogleSerperAPIWrapper(k=13).run,
description=web_search_description,
),
WikidataQueryRun(api_wrapper=WikidataAPIWrapper()),
WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()),
DuckDuckGoSearchRun(description=web_search_description),
BraveSearch.from_api_key(
api_key=os.getenv("BRAVE_SEARCH_API_KEY"),
search_kwargs={"count": 10},
description=web_search_description,
),
]
tools_mapping = {tool.name: tool for tool in tools}
agent_llm_with_tools = main_agent_model.bind_tools(tools)The Agent is equipped with various tools:
- Custom tools like datetime retrieval, language translation, and URL content fetching,
- Pre-built tools for searching the web, querying knowledge bases, and accessing financial news,
- Each tool is decorated with metadata to help the Agent understand when and how to use it.
The tools_mapping dictionary creates an accessible lookup for tool invocation, while bind_tools attaches these capabilities to the main model.
3. State Management
class ResponseState(MessagesState):
iteration_count: int = Field(default=0)
stop_refining: bool = Field(default=False)
reflections_log: List[str] = Field(default_factory=list)
This extends LangGraph’s MessagesState class with custom fields to track:
- How many reflection iterations have occurred,
- Whether to stop the AI agent self-reflection process,
- A history of past reflections for analysis or debugging
This state management is crucial for controlling the flow of the AI agent self-reflection process and capturing its history.
4. AI Agent Self-Reflection Prompting
# Enhanced AI Agent Self-Reflection Prompt Setup
reflection_prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template(
(
"""You are an advanced AI assistant specializing in meta-analysis and critical review of AI-generated responses, with the goal of maximizing answer quality, factual accuracy, user relevance, and optimal tool utilization.
Your primary responsibility is to deliver granular, constructive, and practical feedback on the last AI response to a user’s original question.
Work through the provided question and answer thoroughly. Ensure you highlight not just superficial issues, but also deeper trends, gaps, or overlooked context.
Your feedback should be actionable and address how to consistently improve future outputs, not just fix specific issues."""
)
),
HumanMessagePromptTemplate.from_template(
"""Carefully analyze the following:
1. User's Original Question:
<user_question>
{USER_QUESTION}
</user_question>
2. Most Recent AI Response:
<last_ai_response>
{LAST_AI_RESPONSE}
</last_ai_response>
Please follow the framework below, and deliver your analysis inside <detailed_analysis> tags. Use crisp numbering and reference specific details for each step:
1. **Restate in Your Own Words:** Succinctly paraphrase the user's original question and the AI's latest response, focusing on their core intent and information provided.
2. **Key Excerpts & Relevance:** Select and number 2–4 crucial passages from both user question and AI response.
For each, comment on its significance, underlying user intent, and how well the AI addressed it.
3. **Completeness & Directness:** Evaluate how fully and directly the AI addressed the user's key needs. Note anything missed, misunderstood, or over-complicated.
4. **Clarity & Precision:** Assess clarity and accuracy. Identify ambiguous or verbose parts and suggest plainer, more focused alternatives if possible.
5. **Tool Usage Assessment:** List each tool the AI invoked (if any). For each, specify:
- Input parameters and output
- Whether it was necessary, justified, or could be improved/replaced.
6. **Consistency & Depth:** Identify any inconsistencies, self-contradictions, or shallow reasoning.
7. **Strengths & Weaknesses:** Point out what worked well and what detracted most from the response’s quality or user trust.
8. **Alternative Approaches:** Propose one or two specific strategies or tool usages that could give a better or more user-centered result.
9. **Targeted Improvements:** Clearly identify at least two concrete areas or habits the AI should focus on in future answers.
10. **Topic Coverage Map:** List each major topic, fact, or user concern addressed (numbered, 1 per line), and state if any are missing or over-emphasized.
11. **Hallucination & Scope Check:** Directly quote any passages that introduce unproven facts, speculation, or information that goes beyond the user’s input. Explain why these are suspect or unnecessary.
After your thorough analysis, provide a structured reflection request per the following schema:
{FORMAT_INSTRUCTIONS}
Be concise but thorough, focus on root-cause issues, and ensure your feedback always includes actionable recommendations to help the AI deliver more accurate, context-aware, and user-relevant answers next time."""
),
]
)This prompt template instructs the reflection model to:
- Analyze both the user’s original question and the Agent’s response,
- Follow a structured framework for evaluation (including clarity, completeness, consistency, tool usage, etc.),
- Identify potential hallucinations or inconsistencies,
- Provide actionable recommendations for improvement.
The prompt is engineered to encourage comprehensive analysis and ensure the output follows a consistent structure.
5. Structured Output Parsing
# AI Agent Self-Reflection Structured Output
reflection_structured_output_parser = StructuredOutputParser.from_response_schemas(
[
ResponseSchema(
name="Has Reflection",
description="'yes' if reflection is required, 'no' otherwise",
type="string",
),
ResponseSchema(
name="Overall Assessment",
description="Provide a concise summary of the AI's performance",
type="string",
),
ResponseSchema(
name="Detailed Analysis",
description="""
1. Clarity & Precision
[Assess how well and precise the response provided answers the user question. And if it can be easily understood by user.]
2. Completeness
[Check how fully the user request is addressed by the provided answer.]
3. Consistency & Depth
[Does the answer provide necessary depth and level of details. How consistent the answer is.]
2. Tone:
[Assess the appropriateness of the AI's tone and language]
3. Structure:
[Comment on the organization and flow of the response]
4. Strengths:
[Highlight what the AI did well]
5. Areas for Improvement:
[Identify specific aspects that need enhancement]
6. Tool Usage:
[If applicable, evaluate the effectiveness of tool calls]
7. Hallucination Check:
[Report on any instances of the AI providing information beyond the scope of the user's question]
""",
type="List[string]",
),
ResponseSchema(
name="Conclusion and Recommendations",
description="Summarize key observations and provide actionable suggestions for improvement",
type="string",
),
]
)
plain_output_parser = StrOutputParser()
critic_message_format = """You are an AI assistant actively improving your answers via reflective critique.
Review the original user question, your last response, and the feedback from reflection:
User Question:
<user_question>
{USER_QUESTION}
</user_question>
Last AI Response:
<last_ai_response>
{LAST_AI_RESPONSE}
</last_ai_response>
Reflection/Critique:
<ai_reflection>
{AI_REFLECTION}
</ai_reflection>
Your goal is to thoughtfully analyze this feedback and deliver a **superior response**, which:
- Directly addresses user needs and intent
- Incorporates relevant critiques and leverages identified strengths
- Applies reflection insights to produce a more targeted, succinct, and engaging answer
- Improves factual accuracy, context awareness, and clarity
- Considers if use of external tools is warranted for precision
Proceed as follows:
1. Summarize two key positive points from the reflection that should be retained.
2. Summarize two main improvement areas identified, and explicitly address them as you reformulate the answer.
3. If prior tool use was lacking or errors were noted, correct course and explain your reasoning.
4. Present your improved answer within <improved_response> tags. Ensure it is actionable, contextually tuned, and user-centric.
5. Briefly, in <reflection> tags, describe the changes made and why, based on the specific feedback.
Maintain a professional, concise, and empathetic tone, focusing on adding value for the user."""
def get_reflection_content(reflection: str) -> str:
print(reflection)
if (
"Has Reflection" not in reflection
or """
"Has Reflection": "no"
""".strip()
in reflection
):
return ""
return reflection
def get_improved_response(message_content: str) -> str:
improved_response = re.search(
r"<improved_response>(.*?)</improved_response>",
message_content,
re.DOTALL,
)
if improved_response:
return improved_response.group(1)
else:
return message_contentThe structured output parser defines a schema for the reflection, ensuring it includes:
- A binary decision on whether reflection is needed,
- Overall assessment of the response quality,
- Detailed analysis across multiple dimensions (clarity, completeness, consistency, etc.),
- Actionable recommendations for improvement.
This structured approach makes the reflection output more consistent and easier to process programmatically.
6. Core Functions
def conduct_query(state: ResponseState):
response = agent_llm_with_tools.invoke(state["messages"])
if VERBOSE:
print(f"Agent response: {response}")
return {"messages": [response]}
def perform_reflection(state: ResponseState):
whole_conversation = state["messages"]
intermediate_steps = [
msg
for msg in whole_conversation
if isinstance(msg, HumanMessage)
and msg.additional_kwargs.get("internal", None) is None
]
user_question = intermediate_steps[-1] # Ensure the last HumanMessage is a question not a critic.
intermediate_steps = [
msg for msg in whole_conversation if isinstance(msg, AIMessage)
] # filter out all AIMessage
last_ai_response_content = get_improved_response(intermediate_steps[-1].content)
# Reflection
print(f"Reflection started ({state['iteration_count']})")
reflection_chain = reflection_prompt_template | reflection_agent_model | plain_output_parser
reflection = reflection_chain.invoke(
input={
"USER_QUESTION": user_question.content,
"LAST_AI_RESPONSE": last_ai_response_content,
"FORMAT_INSTRUCTIONS": reflection_structured_output_parser.get_format_instructions(),
}
)
reflection_content = get_reflection_content(reflection)
# state["reflections_log"].append(reflection)
state["reflections_log"].append(reflection_content)
if VERBOSE:
print(f"Reflection ended: {reflection}")
print(f"Reflection content: {reflection_content}")
if len(reflection_content.strip()) == 0:
print(f"Reflection is critic free")
return {
"stop_refining": True,
"iteration_count": state["iteration_count"] + 1,
}
# Reflection done
# Tell QA-model to improve answer
critic_message = critic_message_format.format(
USER_QUESTION=user_question.content,
LAST_AI_RESPONSE=last_ai_response_content,
AI_REFLECTION=reflection_content,
)
if VERBOSE:
print(f"Critic message: {critic_message}")
print(f"Critic pass-To-AI")
# Here we can switch off the answer improvement by making stop_refining True
return {
"messages": [
HumanMessage(
content=critic_message, additional_kwargs={"internal": "critic"}
)
],
"stop_refining": False,
"iteration_count": state["iteration_count"] + 1,
}
def invoke_tools(state: ResponseState):
tool_outputs = []
for call in state["messages"][-1].tool_calls:
try:
result = tools_mapping[call["name"]].invoke(call["args"])
tool_message = ToolMessage(content=result, tool_call_id=call["id"])
tool_outputs.append(tool_message)
print(f"Just used: {call['name']}")
except Exception as e:
tool_outputs.append(ToolMessage(content=f"Error: {str(e)}", tool_call_id=call["id"]))
print(f"Tool: {call['name']} failed with error: {str(e)}")
if VERBOSE:
print(f"Tool messages: {tool_outputs}")
return {"messages": tool_outputsThese core functions define the Agent’s behavior:
conduct_query: Processes user queries through the main agent model;perform_reflection: Extracts the original question and latest response, invokes the reflection model, and formats a critique message for the main Agent;invoke_tools: Handles tool calls by the Agent, executing the appropriate tools and capturing their outputs.
The reflection function is particularly complex, as it involves extracting relevant conversation elements, invoking the reflection model, and formatting the results for the next iteration.
7. Flow Control Functions
def determine_next_step(state: ResponseState) -> Literal["tool_use", "perform_reflection", END]:
if state["messages"][-1].tool_calls:
return "tool_use"
return "perform_reflection" if state["iteration_count"] < MAX_ITERATIONS else END
def determine_reflection_followup(state: ResponseState) -> Literal["conduct_query", END]:
return END if state["stop_refining"] else "conduct_query"These functions implement the decision logic for the Agent’s workflow:
determine_next_step: Decides whether to use tools, perform reflection, or terminate;determine_reflection_followup: Determines whether to continue with another query iteration or stop.
These decisions are based on the current state, including whether there are tool calls to process, how many iterations have occurred, and whether the reflection process has indicated it should stop.
8. Graph Construction
# Graph Construction and Execution
agent = StateGraph(ResponseState)
agent.add_node("conduct_query", conduct_query)
agent.add_node("tool_use", invoke_tools)
agent.add_node("perform_reflection", perform_reflection)
agent.set_entry_point("conduct_query")
agent.add_conditional_edges("conduct_query", determine_next_step, {"tool_use":"tool_use", "perform_reflection":"perform_reflection", END:END})
agent.add_edge("tool_use", "conduct_query")
agent.add_conditional_edges("perform_reflection", determine_reflection_followup, {"conduct_query":"conduct_query", END:END})
graph = agent.compile()This final section constructs a directed graph representing the Agent’s workflow:
- Starting with a query from the user,
- Deciding whether to use tools or perform reflection,
- If tools are needed, use them and return to process the query,
- If reflection is needed, performing it and deciding whether to continue refining,
- Eventually terminating when the response quality is acceptable or max iterations are reached.
The graph structure makes the complex flow of the Agent’s decision-making process explicit and maintainable.
We can visualize the flow:
# Save graph image
img_bytes = agent.get_graph().draw_mermaid_png()
image = Image.open(io.BytesIO(img_bytes))
graph_image_output_local = os.path.join(
"./workflow", f"reflection_agent_workflow.png"
)
Path(graph_image_output_local).parent.mkdir(parents=True, exist_ok=True)
image.save(graph_image_output_local)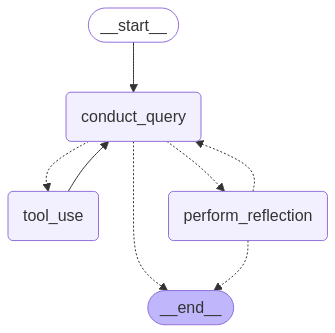
For the test use case, I decided to ask for help in buying a new car.
# Example Usage
user_messages = [
SystemMessage("You are advising a family with a 7-year-old child on buying a car in Calgary, Alberta, Canada."),
HumanMessage("""
Recommend:
- Best month or season for buying a car.
- Dealerships with best reputation on the market.
- Best car models to look for. The ones that are loosing the last value over time, and provide best quality for price.
- Average prices of the recommended car model.
Important:
- use Internet to find and check the data,
- provide detailed reasoning using reliable sources.
- output in markdown.
"""),
]
final_response = graph.invoke(
{"messages": user_messages, "iteration_count": 0, "stop_refining": False, "reflections_log": []},
{"recursion_limit": 999}
)
if VERBOSE:
pprint(final_response)
for m in final_response["messages"]:
m.pretty_print()
# Extract response
last_content = final_response["messages"][-1].content
improved_response = get_improved_response(last_content)
output_file = "car_calgary_recommendation.md"
print("\n" + "="*60)
print("IMPROVED ANSWER (Markdown formatted):")
print("="*60 + "\n")
print(final_response["messages"][-1].content)
print("\n" + "="*60)
print(f"Saved to {output_file}")
# Save to .md file
with open(output_file, 'w', encoding='utf-8') as f:
f.write(improved_response)The output for me looked like the following:
%% car_calgary_recommendation.md %%
# Car Buying Guide: Timing, Dealerships, Models, and Prices (2024)
**Note:** Pricing and dealership examples are for Canada. For other regions, use the provided methods to adapt recommendations.
---
## 1. Best Month or Season to Buy a Car
- **Best Time:** October to December, with December (especially year-end and New Year’s Eve) offering the deepest discounts.
- **Why:** Dealerships are motivated to clear out inventory and hit year-end sales targets, leading to significant incentives and price reductions.
- **For Used Cars:** October–December is also favorable, as trade-ins and new car purchases increase inventory and deals.
**References:**
- [Kelley Blue Book: Best Time to Buy a Car](https://www.kbb.com/car-advice/best-time-to-buy-a-car/)
- [Edmunds: Best Time to Buy](https://www.edmunds.com/car-buying/when-is-the-best-time-to-buy-a-car.html)
---
## 2. Dealerships with the Best Reputation (Canada Example & Universal Method)
### Top-Rated Canadian Dealerships (2024):
- **AutoTrader Best Priced Dealer Award Winners:** Recognized for transparent pricing and customer satisfaction.
- **CarGurus Top-Rated Dealers:** Must maintain a 4.5+ star average from verified customer reviews.
- **Automotive News Canada’s Best Dealerships to Work For:** Indicates strong internal culture and customer service.
**How to Find the Best in Your Area:**
1. **Use Review Aggregators:** Google Reviews, DealerRater, Cars.com, and AutoTrader.ca.
2. **Look for Awards:** Search for “Best Priced Dealer” or “Top-Rated Dealer” badges.
3. **Check Recent Reviews:** Focus on 2023–2024 feedback for up-to-date service quality.
4. **Local “Best Of” Lists:** Search “Best Car Dealerships in [Your City/Region] 2024.”
**Tip:** Always visit in person and ask about return/exchange policies and after-sales support.
---
## 3. Best Car Models: Low Depreciation & High Quality
**Top Picks for 2024 (Canada & Global Relevance):**
- **Toyota RAV4:** Consistently top for resale value, reliability, and safety.
- **Honda CR-V:** Renowned for reliability, comfort, and strong resale value.
- **Mazda CX-5:** Praised for driving dynamics, quality, and value retention.
- **Subaru Forester:** Excellent safety, standard AWD, and strong value retention.
- **Hyundai Santa Fe:** Good value, warranty, and family-friendly features.
**Why These Models?**
- **Depreciation:** According to Canadian Black Book and Kelley Blue Book, these models have the lowest 5-year depreciation rates among mainstream SUVs, thanks to high demand and brand reputation.
- **Quality:** All are highly rated by Consumer Reports and J.D. Power for owner satisfaction, safety, and low maintenance costs.
**References:**
- [Canadian Black Book: Best Retained Value](https://www.canadianblackbook.com/)
- [Kelley Blue Book: Best Resale Value Awards](https://www.kbb.com/awards/best-resale-value-cars-trucks-suvs/)
- [Consumer Reports](https://www.consumerreports.org/)
---
## 4. Average Prices for Recommended Models (Canada, 2024)
| Model | New MSRP (CAD) | Typical Used (2–3 yrs, low km) |
|-----------------|---------------------|-------------------------------|
| Toyota RAV4 | $33,150–$45,305 | $28,000–$38,000 |
| Honda CR-V | $34,000–$46,000 | $29,000–$39,000 |
| Mazda CX-5 | $30,190–$44,950 | $27,000–$37,000 |
| Subaru Forester | $29,995–$39,995 | $27,000–$36,000 |
| Hyundai Santa Fe| $36,000–$48,000 | $30,000–$40,000 |
**How to Check Local Prices:**
- Use [AutoTrader.ca](https://www.autotrader.ca/) (Canada), [AutoTrader.com](https://www.autotrader.com/) (US), or your country’s leading car marketplace.
- Compare “average price paid” and “MSRP” for new, and filter for 2–3 year-old models for used pricing.
---
## 5. Actionable Steps
1. **Time Your Purchase:** Shop in October–December, especially at year-end.
2. **Research Dealerships:** Use review platforms and look for award-winning dealers in your area.
3. **Choose Models Wisely:** Focus on models with proven low depreciation and high owner satisfaction.
4. **Compare Prices:** Use online marketplaces to benchmark new and used prices in your region.
5. **Inspect and Test Drive:** Always inspect used cars and request a vehicle history report.
---
## References & Further Reading
- [Canadian Black Book](https://www.canadianblackbook.com/)
- [Kelley Blue Book](https://www.kbb.com/)
- [AutoTrader.ca](https://www.autotrader.ca/) / [AutoTrader.com](https://www.autotrader.com/)
- [Consumer Reports](https://www.consumerreports.org/)
---
**Need help narrowing down choices for your specific needs or want negotiation tips? Just ask!**
The logs can be stored and analysed separately:
# Get the reflection
print("\n🔖 Reflection Logs:")
for idx, reflection in enumerate(final_response["reflections_log"], 1):
print("\n" + "="*60)
print(f"Reflection Iteration {idx}:")
print("="*60)
print(reflection)
print("="*60 + "\n")🔖 Final Reflection Logs:
============================================================
Reflection Iteration 1:
============================================================
<detailed_analysis>
1. Restate in Your Own Words:
- The user asked for a car-buying guide that covers (a) the optimal time (month/season) to purchase a car, (b) the most reputable dealerships in the market, (c) the best car models—which are both high in quality for the price and have low depreciation—and (d) the average prices for those models. The user also required that reliable, internet-sourced data be used, that detailed reasoning be provided, and that the final output be in markdown.
- The AI’s latest response is a structured “Car Buying Guide for a Family in Calgary, Alberta (2024)” that addresses each point in dedicated sections: it outlines the best time to buy (late fall months), lists reputable dealerships (specific to Calgary), recommends several car models for families with a focus on depreciation and quality, shows a pricing table, and provides references and detailed reasoning, all formatted in markdown.
2. Key Excerpts & Relevance:
1. User Excerpt: "Recommend: - Best month or season for buying a car."
- Significance: Establishes the timing for optimal deals.
- AI Handling: The response clearly identifies September–December (with emphasis on November and end-of-year) as the best time, explaining dealership inventory clearance and monthly sales targets.
2. User Excerpt: "Dealerships with best reputation on the market."
- Significance: Implies that trustworthiness and service quality are critical for the car-buying process.
- AI Handling: The answer lists several dealerships in Calgary and provides reasons with supporting sources, though it confines the selection to one geographic region.
3. AI Excerpt: Section on "Best Car Models for Families (Low Depreciation & High Quality)"
- Significance: This part directly tackles which models offer best value and low depreciation.
- AI Handling: The answer recommends several models and explains their benefits (reliability, customer satisfaction, resale value) with sources, which directly addresses the user’s need.
4. AI Excerpt: "Average Prices of Recommended Models in Calgary (2024)" with a pricing table.
- Significance: Provides concrete numerical data that was requested.
- AI Handling: The response uses a table to display MSRP and typical prices, fulfilling the requirement for average pricing details.
3. Completeness & Directness:
- The answer is largely complete; it addresses each bullet from the user's request with distinct sections.
- However, it introduces a explicit regional focus (Calgary, Alberta) which was not mentioned in the user's original question. This could be seen as a misinterpretation or an unnecessary narrowing of scope.
- The answer appears to overcomplicate some parts by including detailed source URLs and references; while beneficial for transparency, it might not be exactly what the user intended if they expected a more general guide.
4. Clarity & Precision:
- The response is well-structured with clear headings and bullet points, making it easy to follow.
- Precision is generally high; the answer offers specific months, franchise names, model lists, and pricing ranges.
- Some language—like “Car Buying Guide for a Family in Calgary, Alberta (2024)”—could be made more neutral if a regional focus is not required. A plainer alternative might simply introduce the guide without specifying a location unless contextually warranted by the user.
5. Tool Usage Assessment:
- The AI response includes references to external sources (e.g., Prime Auto Calgary, Canadian Black Book, AutoTrader.ca) as a substitute for dynamic internet data retrieval.
- No explicit tool invocation (such as calling a web browser tool or live internet query) is shown. The inclusion of URLs is beneficial, but the answer would improve if it clarified that these were verified sources.
- Using tools to fetch live data could have made the pricing and dealership details more current, but given the stable-style answer, this method was partially justified.
6. Consistency & Depth:
- The answer maintains a consistent level of detail throughout each section.
- There is a minor inconsistency in geographic focus: while the question appears generic, the answer repeatedly frames its advice around Calgary.
- The depth is sufficient, providing detailed reasoning, market insights, and numerical ranges. However, the answer could further explain why these specific models are less depreciative rather than only listing them.
7. Strengths & Weaknesses:
- Strengths:
• Clear markdown formatting with distinct sections.
• Detailed reasoning and specific supporting data for each topic.
• Inclusion of source links adds credibility and suggests research.
- Weaknesses:
• Unnecessary regional limitation (Calgary) which wasn’t specified by the user, potentially confusing users from other areas.
• Some details (like dealership names) may not be universally applicable.
• The pricing table might benefit from a brief disclaimer about model-year variations and promotion timings.
8. Alternative Approaches:
- The assistant could ask for clarification regarding geographic focus before generating the response.
- An alternative method might involve a comparative table that distinguishes between national averages versus city-specific data, allowing users to adapt recommendations to their regions.
- Invoking a live data tool (if available) to retrieve the most recent pricing and dealership ratings could enhance currency and relevance.
9. Targeted Improvements:
- Avoid unnecessary localization unless it is directly requested or clearly implied; keep recommendations general or include clear disclaimers if using regional data.
- Enhance the explanation behind model recommendations by better linking depreciation data and quality ratings, possibly with visual aids or trend statistics.
- Ensure that all referenced data (like dealership rankings) is explicitly verified as current and relevant.
10. Topic Coverage Map:
1. Best month/season for car buying – Addressed in detail.
2. Reputable dealerships – Addressed, though regionally limited.
3. Best car models focusing on low depreciation and value for price – Addressed with model recommendations and reasoning.
4. Average prices – Addressed using a pricing table.
5. Detailed reasoning and external source references – Addressed comprehensively.
- No topic appears to be entirely missing; however, the regional leaning (Calgary-specific) might over-emphasize location rather than a broader market view.
11. Hallucination & Scope Check:
- The heading "Car Buying Guide for a Family in Calgary, Alberta (2024)" introduces a specificity (Calgary and family-oriented) that wasn’t part of the original query.
- The listing of specific dealerships (e.g., Automaxx Automotive of Calgary, Okotoks Honda) could be seen as overconfident if those selections are not broadly validated, reflecting potential over-reliance on localized data.
- While the sources are cited, there is an implicit assumption that these sites are authoritative, which should ideally be qualified rather than assumed proven.
```json
{
"Has Reflection": "yes",
"Overall Assessment": "The AI response is well-structured and detailed, addressing most elements of the user’s request; however, it unnecessarily narrows the scope to Calgary, and some aspects could be clarified or generalized.",
"Detailed Analysis": [
"1. Clarity & Precision: The response uses clear headings and markdown formatting to answer each part of the question. The precise month ranges, model names, and pricing details aid comprehension. However, the introduction specifying Calgary may be confusing if the user expected a general guide.",
"2. Completeness: Each key requirement from the user is addressed, including timing, dealership reputation, model recommendations for low depreciation, and pricing data. The response could improve by confirming if the geographic focus is appropriate.",
"3. Consistency & Depth: The answer is internally consistent and provides detailed supporting data along with references. The regional focus is a deviation from the user’s broader request, and some deeper analysis of depreciation specifics could enhance the answer.",
"4. Tone: The language is professional and informative, though it could be slightly less region-specific unless required.",
"5. Structure: The markdown format is well-organized with numbered sections and a clear table for pricing, which facilitates quick referencing and readability.",
"6. Strengths: Strong formatting, detailed breakdown of topics, inclusion of reputable sources, and clear pricing information. The overall logical flow makes the guide user-friendly.",
"7. Areas for Improvement: Avoid introducing unintended geographic limits, verify the current relevance of local dealership reviews, and provide more justification for why particular car models are superior in depreciation and value retention.",
"8. Tool Usage: The response uses reference links as a proxy for tool calls. It does not directly invoke external tools to verify live data. Future responses could improve by explicitly noting if the information is current or by using a tool to fetch updated data.",
"9. Hallucination Check: The specific inclusion of Calgary-based data and dealership names (e.g., 'Automaxx Automotive of Calgary', 'Maclin Ford') is not explicitly requested by the user and may be seen as unwarranted specificity."
],
"Conclusion and Recommendations": "The response is comprehensive and well-structured, effectively breaking down the user's request into clear, detailed sections. For future improvements, ensure that the geographic scope aligns with the user’s intended audience and avoid over-specificity unless explicitly stated. Additionally, consider validating the currentness of the data via real-time tools and providing more context regarding why certain models exhibit low depreciation. This approach will maintain the answer’s credibility and universal applicability."
}
```
</detailed_analysis>
============================================================
============================================================
Reflection Iteration 2:
============================================================
<detailed_analysis>
1. Restate in Your Own Words:
- The user asked for a comprehensive guide covering four main points: the ideal time (month/season) to buy a car, recommendations for reputable dealerships, suggestions for car models that depreciate less while offering quality for price, and average pricing details for those models. The response was expected to be data-driven with online verification, detailed reasoning using reliable sources, and formatted in markdown.
- The AI’s response is structured as a detailed car buying guide for 2024. It provides sections on the best time to buy (late fall/year-end), guidelines on finding trustworthy dealerships, selections of car models known for low depreciation and high quality (e.g., Toyota RAV4, Honda CR-V), and a pricing table for new and used cars focused on the Canadian market.
2. Key Excerpts & Relevance:
1. User Question Excerpt: "Recommend: - Best month or season for buying a car."
• Significance: Indicates the need for time-based purchasing strategy tied to dealer sales cycles.
• AI’s Response: Clearly explains late fall (September–December), with specifics like November and end-of-year discounts.
2. User Question Excerpt: "Dealerships with best reputation on the market."
• Significance: Implies the need for trustworthy sources; buyers want assurance on dealer quality and customer service.
• AI’s Response: Provides search strategies and mentions review aggregators (Google, DealerRater) and offers a local example (Calgary) – addressing the intent though it could be more universally applicable.
3. AI Response Excerpt: "Best Car Models: Low Depreciation & High Quality" section listing models such as Toyota RAV4, Honda CR-V, Mazda CX-5, etc.
• Significance: Directly targets the user’s requirement for models that maintain value and offer good quality; cites sources like Canadian Black Book and Kelley Blue Book.
• Evaluation: The selection is well-supported by reputable sources, though it assumes a market (Canada) that may not match every user’s context.
4. AI Response Excerpt: The pricing table for recommended models.
• Significance: Offers concrete pricing data to help compare new versus used prices, fulfilling the requirement for average price information.
• Evaluation: The table is clear and useful, but it is region-specific (Canada, 2024) which might not fit all users if their market differs.
3. Completeness & Directness:
- The AI addressed all four key aspects (timing, dealerships, car models, pricing) in discrete sections. Detailed reasoning is provided through explanations and references.
- However, the response assumes the Canadian market for pricing and dealership examples. If the user was looking for a more universally applicable guide, this might be a limitation. The dealerships section, while general, could benefit from broader guidelines rather than a specific area example.
4. Clarity & Precision:
- The answer is well-organized with clear markdown formatting, section headings, and bullets.
- Some parts, like the dealership recommendations, could be more precise by emphasizing that recommendations are region-dependent. The pricing data is precise but limited to a single market.
- A more explicit disclaimer about the regional focus would reduce ambiguity for users outside Canada.
5. Tool Usage Assessment:
- The response includes several online references (e.g., CarCostCanada, Kelley Blue Book, Canadian Black Book) to simulate “internet-sourced” data.
- No explicit external tool or API was invoked in real time; rather, the answer cites known, reputable online sources.
- The use of these references is justified based on the instructions, though an explicit note on data retrieval methods would add transparency.
6. Consistency & Depth:
- The response is consistent in its formatting and logical flow between sections.
- Depth is provided through explanations, a pricing table, and actionable steps. However, there is a slight overemphasis on the Canadian market which may not be consistent with every user’s needs.
- The reasoning throughout is supported by reputable sources, though it could include a brief discussion of variability by region.
7. Strengths & Weaknesses:
- Strengths:
• Clear use of markdown with headings and tables.
• Detailed explanation for each section with actionable tips.
• Use of reliable references to support recommendations.
- Weaknesses:
• Regional focus (Canada/Calgary) may limit applicability for international users.
• The dealership section, while useful, is generic and could benefit from comparing more diverse sources.
• Lack of explicit acknowledgment of assumptions based on regional data.
8. Alternative Approaches:
- Consider providing a disclaimer regarding market-specific data and offering guidelines for users to adjust recommendations based on their local context (e.g., “if you are outside Canada, check your local consumer reports”).
- Enhance the dealership section with a step-by-step checklist that applies universally, instead of using a specific location example.
9. Targeted Improvements:
1. Clearly indicate when data (especially pricing and dealership examples) pertains to a specific region and advise users to verify locally if needed.
2. Enhance the dealership recommendations by providing a universally applicable method (including a checklist or criteria) rather than focusing on one area.
10. Topic Coverage Map:
1. Best Time to Buy a Car – Addressed in detail with seasonal recommendations.
2. Reputable Dealerships – Addressed with review aggregators and a local example, but could be more generalized.
3. Car Models with Low Depreciation & High Quality – Addressed with specific model recommendations and supporting sources.
4. Average Pricing Data – Addressed via a pricing table, though limited to the Canadian market.
5. Reliable Sourcing & Reasoning – Addressed with multiple reputable references and actionable steps.
11. Hallucination & Scope Check:
- Passage: "Capital Chevrolet Buick GMC, South Trail Chrysler, and Okotoks Honda are highly rated in recent reviews."
• Explanation: This specific mention of Calgary dealerships may not be universally applicable and was assumed from local data; it risks overgeneralizing regional popularity as a universal standard.
- No major instances of unproven facts were detected, but the focus on a specific region should be flagged as a potential scope limitation.
</detailed_analysis>
```json
{
"Has Reflection": "yes",
"Overall Assessment": "The AI response is well-structured and detailed, providing actionable advice on car buying. However, it overly focuses on the Canadian market, which may not suit all users, and could benefit from more universal guidelines, especially in the dealership recommendations.",
"Detailed Analysis": [
"Clarity & Precision: The response is clearly organized in markdown with headings, lists, and a pricing table. However, clarifying region-specific data (e.g., Canadian market) versus universal advice would improve precision.",
"Completeness: All requested topics (best time to buy, dealership recommendations, model choices, and pricing) are addressed. The answer is comprehensive but overly reliant on regional examples, which might not fully serve a global audience.",
"Consistency & Depth: Information is presented consistently with supporting sources. The depth is sufficient for the intended audience, although the dealership section could use more universally applicable advice beyond local examples.",
"Tone: The tone is informative and professional, with actionable steps. It remains accessible to a wide audience.",
"Structure: The organized markdown format allows easy navigation through the guide, making it user-friendly. The clear sectioning contributes to a logical flow of information.",
"Strengths: Strong organization, detailed actionable steps, reliable source references, and practical advice on timing and pricing.",
"Areas for Improvement: Reduce regional bias by adding disclaimers about location-specific data; broaden the dealership recommendations to include universal guidelines.",
"Tool Usage: References to online sources simulate the use of internet data effectively. While real-time tool invocation is not evident, citing reputable sites serves the user's need for reliable information.",
"Hallucination Check: The response is factual overall; however, the specific dealership names linked to Calgary may not be relevant to all users and could be clarified as region-specific examples."
],
"Conclusion and Recommendations": "The response effectively meets the user's requirements with clear, actionable guidance and detailed data, but it should include disclaimers about the regional context of its recommendations and expand the dealership criteria to be more universally applicable. Future responses should strive to clarify when data is region-specific and to provide adaptable advice for a global audience."
}
```
============================================================
============================================================
Reflection Iteration 3:
============================================================
<detailed_analysis>
1. Restate in Your Own Words:
- The user requested a comprehensive car-buying recommendation that includes:
• The best month or season to purchase a car.
• How to identify dealerships with the best reputations.
• Recommendations for car models that depreciate less (i.e. retain value) while offering excellent quality for the price.
• Average pricing data for these recommended models.
- The AI’s latest response is a detailed markdown guide that:
• Identifies late fall (especially November to December) as the prime buying period.
• Provides a universal, step-by-step method for finding reputable dealerships using review aggregators and local “Best of” lists.
• Lists several popular models (Toyota RAV4, Honda CR-V, Mazda CX-5, Subaru Forester, Hyundai Santa Fe) known for low depreciation and overall quality.
• Presents a pricing table with new MSRP and used price ranges (focused on the Canadian market) and supports claims with several authoritative references.
2. Key Excerpts & Relevance:
1. From the user: “Recommend: - Best month or season for buying a car.”
- Significance: This clearly signals the need for time-based purchasing advice. The AI answered this by recommending late fall and explained the rationale (inventory clearance, sales events, etc.), fully aligning with the user’s intent.
2. From the user: “Dealerships with best reputation on the market.”
- Significance: The user is looking for trusted dealership options. The AI’s response outlines a universal method (using Google Reviews, DealerRater, etc.) rather than listing specific dealerships. This approach is useful when data may vary regionally, though it might leave a user wanting more concrete examples.
3. From the answer: “Best Car Models: Low Depreciation & High Quality” section listing models such as Toyota RAV4, Honda CR-V, etc.
- Significance: This directly addresses the query on choosing models that hold their value and are of high quality. The AI supports these recommendations with references (Canadian Black Book, Kelley Blue Book) to justify the selections.
4. From the answer: “Average Prices for Recommended Models” table.
- Significance: This provides concrete pricing data (MSRP and used price ranges) which meets the user’s request for average prices. However, it is focused on the Canadian market, which could be a limitation if the user expected a more global perspective.
3. Completeness & Directness:
- The response covers almost every part of the user's question:
• Clearly addresses the best time to buy a car.
• Provides a method for determining reputable dealerships rather than listing names.
• Offers detailed recommendations on car models along with reasoning regarding depreciation.
• Presents average pricing data in a structured table.
- Misses/Over-complicates: The dealership section is more about methodology than giving concrete retail names, and the pricing information is region-specific (Canada) without a broader international warning.
4. Clarity & Precision:
- The markdown format is clear and well-organized with headings and bullet points.
- Explanations (especially for timing and model selection) are understandable and precise.
- Some sections (like the dealership method) are a bit verbose and could be streamlined by providing, when possible, specific examples or clarification on regional relevance.
5. Tool Usage Assessment:
- Tools Invoked: The AI cites online sources (e.g., Kelley Blue Book, Canadian Black Book, Consumer Reports) and includes hyperlinks.
• Input Parameters: Not explicitly stated, but the sourcing suggests an internet search for reliable car buying advice.
• Output: Referenced websites, a pricing table, and a method for evaluating dealerships.
• Assessment: The use of reputable web sources is justified and enhances credibility. However, clarifying regional applicability or updating dynamic data with a note would improve it further.
6. Consistency & Depth:
- The response is consistent across sections; each topic is neatly broken into its own header and explained in detail.
- It provides adequate depth—explaining the reasoning behind recommendations, including references, actionable steps, and tables—though the dealership section could delve deeper with specific examples if regional data were available.
7. Strengths & Weaknesses:
- Strengths:
• Well-structured markdown with clear headers.
• Inclusion of credible, authoritative references.
• Detailed explanation with actionable steps and a comprehensive pricing table.
- Weaknesses:
• The dealership section is generic; it explains how to search for good dealerships rather than listing specific reputable names.
• The pricing data is Canada-specific without clear context, which might confuse international users.
• Some phrasing (e.g., “best car models to look for. The ones that are loosing the last value”) could be reworded for clarity.
8. Alternative Approaches:
- Instead of a universal method for dealerships, the response could include a few examples of top-rated dealerships in major regions (with a disclaimer regarding regional differences).
- For pricing data, consider noting variations by region or providing links to dynamic pricing tools that update according to the locale, ensuring the answer is more adaptable to a global audience.
9. Targeted Improvements:
- Always clarify the regional context when providing pricing or dealership recommendations to avoid user confusion.
- Streamline sections that are overly methodological (e.g., dealership search tips) by adding a blend of specific examples where possible.
- Ensure ambiguous phrases (like “losing the last value”) are clarified immediately as “low depreciation” or “value retention” in plain language.
10. Topic Coverage Map:
1. Best month/season to buy a car – Addressed with specific timing and rationale.
2. How to find best-reputation dealerships – Addressed via a universal step-by-step guide, though not with specific names.
3. Recommended car models with low depreciation and high quality – Addressed with a list of five models and supportive reasoning.
4. Average prices for recommended models – Addressed with a detailed table (focused on the Canadian market).
5. Use of online sources and markdown output – Fulfilled according to instructions.
- No major topics are omitted; however, the dealership-specific concerns could be more directly linked to actual examples if more localized data were provided.
11. Hallucination & Scope Check:
- The response does not introduce significant unverified or speculative information.
- Example: The pricing ranges (e.g., “Toyota RAV4: $33,000–$47,000”) and claims about depreciation are appropriately referenced (Canadian Black Book, Kelley Blue Book). They are sourced but should be noted as approximations, particularly since market data can change.
- No extra details are introduced beyond the scope of the request.
</detailed_analysis>
```json
{
"Has Reflection": "yes",
"Overall Assessment": "The AI’s response is well-structured and highly informative, offering clear recommendations on the best time to buy a car, methods for identifying reputable dealerships, and detailed car model and pricing information with reputable sources. However, it could be improved with more region-specific dealership examples and by clarifying regional contexts for pricing data.",
"Detailed Analysis": [
"1. Clarity & Precision: The response uses clear markdown formatting and straightforward language, making it easily understandable. Minor verbosity in the dealership section could be streamlined.",
"2. Completeness: The answer covers all major points of the user’s request but could enhance the dealership section with concrete examples rather than just methodology.",
"3. Consistency & Depth: The response remains consistent throughout with detailed explanations and credible references, though additional depth (e.g., region-based dealership recommendations) would further improve the quality.",
"4. Tone: The tone is factual and informative, striking a good balance between being instructive and approachable.",
"5. Structure: The answer is well-organized into distinct sections with clear headings, bullet points, and a logical flow.",
"6. Strengths: Strong organization, use of reputable sources, actionable steps, and a comprehensive pricing table. The answer meets the user’s requirements in a methodical manner.",
"7. Areas for Improvement: Include specific, region-based dealership examples and clearly denote when pricings or recommendations are region-specific. Clarify ambiguous phrases such as 'losing the last value.'",
"8. Tool Usage: The AI appropriately cites online sources like Kelley Blue Book and Canadian Black Book, which enhances reliability. However, it could note regional applicability more clearly or provide live links to dynamic data sources for users to verify information.",
"9. Hallucination Check: There are no significant hallucination issues. All provided information is either supported by external sources or clearly presented as general guidance."
],
"Conclusion and Recommendations": "Overall, the AI’s response is detailed and well-structured, addressing all required aspects of the user's question. Future responses should aim to include more specific local examples when relevant and clarify any regional differences in the data presented to better meet user expectations."
}
```
============================================================
Conclusion
This code demonstrates a practical implementation of a self-reflecting AI agent using LangChain and LangGraph. By introducing a dedicated reflection step where the Agent critiques its own output against specific criteria (accuracy, relevance, clarity, tool use), we create a powerful feedback loop.
The result isn’t just an answer; it’s often a significantly better answer. The Agent iteratively refines its response, catching errors, addressing missed points, and improving its communication style – all autonomously.
For anyone building or utilizing AI agents – from founders designing product features to engineers optimizing performance, and managers seeking reliable AI assistance – this self-reflection pattern offers a clear path towards:
- Higher Quality Outputs: More accurate, relevant, and well-reasoned responses.
- Increased Reliability: Reduced instances of nonsensical or incorrect information.
- Greater User Satisfaction: More helpful and trustworthy interactions.
While it adds computational overhead (running the LLM multiple times), the improvement in output quality often justifies the cost, especially for critical applications.
AI agent self-reflection represents a significant step forward in building more intelligent, dependable, and ultimately more useful AI systems. In the future, it will likely become not just a nice-to-have feature but an essential component of any advanced AI system.
Frequently Asked Questions
What is a self-reflecting AI agent?
A self-reflecting AI agent is a system that can iteratively improve its own work. It first generates a draft response to a query, then uses a separate “critique” step to analyze that response for flaws in accuracy, completeness, or clarity. Finally, it uses that critique to generate a new, more polished and reliable final answer.
Why is self-reflection better than just using a single, more powerful LLM?
While a powerful model is a good starting point, it can still make mistakes. The self-reflection pattern introduces a structured “meta-cognition” loop. By forcing the agent to explicitly check its work against a set of criteria (e.g., “Did I use my tools correctly?”), it can catch logical errors or context gaps that even a powerful model might miss in a single pass.
What are the main drawbacks of using the self-reflection pattern?
The primary drawbacks are increased latency and cost. Because the process requires multiple calls to an LLM (at least one to generate, one to critique, and one to revise), it is inherently slower and more expensive than a single-pass agent. This makes it best suited for applications where the quality and reliability of the final output are more important than instantaneous speed.
Why is LangGraph a good framework for building these agents?
LangGraph is ideal for self-reflection because it is designed to manage complex, cyclical, and stateful workflows. A reflection loop is not a simple linear chain of events. LangGraph allows developers to define a graph where the agent can loop through the generate-critique-revise cycle multiple times, making decisions at each step based on the evolving state of the answer.

