
Key Takeaways
- Solve the “Last Mile” of BI: A conversational AI agent bridges the gap between static dashboards and specific, ad-hoc user questions, making data insights accessible to everyone.
- Multimodal LLMs are Key: The agent uses a multimodal model (like Gemini or GPT-4o) to “see” and understand the visual context of dashboard charts, allowing it to answer questions like “What does the bar chart show?”
- Dual-Approach to Data: The agent combines visual understanding of the dashboard with the ability to generate and execute its own SQL queries against the underlying database for fresh, precise analysis.
- LangGraph for Orchestration: The agent’s complex workflow—identifying charts, generating SQL, handling errors, and synthesizing answers—is built and managed using LangGraph, making the logic robust and stateful.
Business Intelligence (BI) dashboards are invaluable tools, offering visual summaries of complex data, tracking key performance indicators (KPIs), and helping organizations make data-driven decisions. However, even the most well-designed dashboards can sometimes feel static. What if you have a specific, ad-hoc question that isn’t directly answered by the pre-built charts? What if you’re not a data expert and find complex filtering or data interpretation challenging? Enter the Conversational AI Agent for BI Dashboards – an intelligent assistant designed to bridge this gap. Imagine asking questions about your dashboard in plain English, just like you’d ask a colleague, and getting immediate, accurate answers. This agent doesn’t just look at the pretty pictures; it understands the visual context of your charts and has access to the underlying database, allowing it to perform fresh analysis on the fly.
In this article, we’ll explore the practical implementation of such an agent, including its business case, benefits, architecture, the technologies powering it, and a detailed walkthrough of the code. By the end, you’ll see how you can build your own AI-powered assistant to supercharge your BI analysis.
Why The AI Agent for BI?
Traditional BI dashboards, while powerful, come with certain limitations that a conversational agent can address:
- The “Last Mile” Problem: Dashboards present aggregated data. When users need to drill down, combine information in new ways, or ask highly specific questions, they often hit a wall. They might need to export data for manual analysis or request a custom report, leading to delays.
- Information Overload & Complexity: Modern dashboards can be dense with information. Users might feel overwhelmed or unsure how to find the exact slice of data they need.
- Skill Gap: Not every decision-maker is a seasoned data analyst. Interpreting complex visualizations or knowing how to manipulate dashboard filters effectively can be a barrier.
- Need for Speed: In today’s fast-paced business environment, answers are needed quickly. Waiting for a data team to fulfill a request isn’t always feasible.
- Ad-hoc Queries: Business is dynamic. New questions arise constantly that dashboard designers couldn’t anticipate.
A conversational AI agent for BI acts as an intelligent intermediary. It understands the user’s natural language query, identifies the relevant context from the dashboard’s visuals, and if necessary, queries the database to fetch precise information, delivering a clear, concise answer. This empowers users to explore data more freely and intuitively.
Implementing a conversational AI agent for BI offers a multitude of advantages:
- Democratization of Data Insights: Makes complex data accessible to a wider audience, regardless of their technical skills. Anyone can ask questions and get answers.
- Increased Efficiency: Users get answers in seconds or minutes, not hours or days. This drastically reduces the time spent on manual data wrangling or waiting for support.
- Deeper, Contextualized Insights: By combining multimodal understanding (textual question + visual chart context) with direct database access, the agent can provide highly relevant and nuanced answers that might be missed through manual exploration alone.
- Improved Decision-Making: Faster access to more precise information empowers users to make better, more timely, data-driven decisions.
- Enhanced User Engagement: Interacting with data becomes a conversation, making the BI experience more intuitive, engaging, and less intimidating.
- Reduced Load on BI/Data Teams: Automates responses to many common and ad-hoc questions, freeing up specialized data professionals to focus on more strategic and complex analytical tasks.
- Proactive Potential: Future iterations could even allow the agent to proactively suggest insights or flag anomalies, acting as a true analytical partner.
AI Agent for BI: Solution Structure
The conversational AI agent for BI solution we will discuss today has the following file structure:
# bi_agent/
# ├── dashboard/
# │ ├── chart1_sales_trend.png
# │ ├── chart2_revenue_by_region.png
# │ └── sales_dashboard.png # Example dashboard image
# │ └── ... # Other charts images
# ├── data.sqlite # SQLite database file
# ├── sales-data.csv # Sales data file (source)
# ├── main.py # Main script to run the agent
# ├── utils.py # Utility methods
# ├── load_data.py # Utility to load CSV to SQLite
# └── requirements.txt # Python dependencies
Let’s break down each component:
- bi_agent/: The root directory for our project.
dashboard/: This folder holds images of your BI dashboard charts (e.g.,sales_dashboard.png,chart1_sales_trend.png). These images are crucial. Our AI agent for BI uses a multimodal Large Language Model (LLM) that can “see” these charts, helping it understand the visual context of the user’s question (e.g., “What’s the trend in the bar chart on the left?”).data.sqlite: This is our SQLite database. It stores the structured data that powers the dashboard visualizations. The AI agent for BI will query this database to find answers.sales-data.csv: The raw data source. In this example, it’s a CSV file containing sales information. This file is used byload_data.pyto populate thedata.sqlitedatabase.load_data.py: A Python script responsible for ETL (Extract, Transform, Load). It reads data fromsales-data.csv, performs any necessary cleaning or transformation (though minimal in this example), and loads it into a table withindata.sqlite.utils.py: A collection of helper functions that support the main agent logic. This includes functions for database connectivity, retrieving the database schema, executing SQL queries, and encoding images into a format suitable for the LLM. This promotes modularity and keepsmain.pycleaner.main.py: This is the heart of our AI agent for BI. It contains the core logic for:- Initializing the LLM.
- Defining the agent’s state and workflow using LangGraph.
- Handling user interaction (taking questions, providing answers).
- Orchestrating the steps involved in answering a question: identifying relevant charts, generating SQL queries, executing them, and synthesizing the results into a natural language response.
requirements.txt: This standard Python file lists all the external libraries and their versions needed to run the project (e.g.,langchain,pandas,Pillow). This ensures that anyone can set up the necessary environment to run the AI agent for BI.
AI Agent for BI: Technologies
This solution leverages several powerful open-source technologies:
- Python and Pandas: I think there is no need to explain these two.
- SQLite: A lightweight, serverless, self-contained SQL database engine. It’s perfect for local development and applications where a full-scale database server isn’t necessary. The data is stored in a single file (
data.sqlite). - Langchain: A comprehensive framework designed to simplify the development of applications powered by Large Language Models (LLMs). It provides tools and abstractions for managing prompts, interacting with LLMs, chaining operations, and more.
ChatVertexAI(using Gemini Pro): This is the LLM from Google Cloud used in our example. It’s a powerful multimodal model, meaning it can process and understand information from both text and images. This is key for our agent to “see” the dashboard charts. (Alternatively, one could useChatOpenAIwith models like GPT-4o).- Pydantic Models: Langchain leverages Pydantic for defining data structures. We use them to specify the expected format of the LLM’s output (e.g., for structured chart identification or SQL query generation), making the responses more reliable and easier to parse.
- LangGraph: A Langchain library for building stateful, multi-actor applications by representing them as cyclical graphs. It’s ideal for creating agents that involve multiple steps, decision points, and loops. We use it to define the flow of our agent: from understanding the question to providing the final answer.
- Pillow (PIL Fork): A Python Imaging Library used for opening, manipulating, and saving image files. Here, it’s used to resize dashboard chart images and prepare them for encoding.
- Base64 Encoding: A method to convert binary data (like images) into a text string. This allows us to embed the images directly into the prompts sent to the multimodal LLM.
AI Agent for BI: Implementation
Let’s examine the key Python files and their roles.
load_data.py: Populating the Database
This script is responsible for getting your data into a queryable format.
# File load_data.py
import pandas as pd
import sqlite3
import os
# --- Configuration ---
# SETTINGS: Update these variables according to your file names
CSV_FILE_PATH = 'sales-data.csv' # The name of your CSV file
DB_FILE_PATH = 'data.sqlite' # The name of the SQLite database file to create/use
TABLE_NAME = 'dashboard_data' # The name for the table within the database
# How to handle the data if the table already exists:
# 'replace': Drop the table before inserting new values (good for full refreshes)
# 'append': Insert new values to the existing table (good for adding more data)
# 'fail': Raise a ValueError if the table exists (default, less common for loading)
IF_EXISTS_STRATEGY = 'replace'
# --- End Configuration ---
def load_csv_to_sqlite(csv_path=CSV_FILE_PATH, db_path=DB_FILE_PATH, table_name=TABLE_NAME, if_exists='replace'):
"""
Reads data from a CSV file and loads it into a specified table in an SQLite database.
Args:
csv_path (str): Path to the CSV file.
db_path (str): Path to the SQLite database file.
table_name (str): Name of the table to load data into.
if_exists (str): Action to take if the table already exists ('replace', 'append', 'fail').
"""
if not os.path.exists(csv_path):
print(f"Error: CSV file not found at '{csv_path}'")
return
try:
# Read the CSV file into a pandas DataFrame
print(f"Reading CSV file: {csv_path}...")
df = pd.read_csv(csv_path)
print(f"Read {len(df)} rows from CSV.")
if df.empty:
print("Warning: CSV file is empty. No data will be loaded.")
return
# Data Cleaning/Preparation (Optional but often Recommended)
# Example: Clean column names to be safe for SQL (remove spaces, special chars)
# df.columns = df.columns.str.strip().str.lower().str.replace(' ', '_').str.replace(r'[^a-zA-Z0-9_]', '', regex=True)
# print("Cleaned column names:", df.columns.tolist())
except FileNotFoundError:
print(f"Error: The file '{csv_path}' was not found.")
return
except pd.errors.EmptyDataError:
print(f"Error: The CSV file '{csv_path}' is empty.")
return
except Exception as e:
print(f"Error reading CSV file '{csv_path}': {e}")
return
try:
# Create a connection to the SQLite database
# If the database file doesn't exist, it will be created automatically.
print(f"Connecting to database: {db_path}...")
# Using 'with' ensures the connection is properly closed even if errors occur
with sqlite3.connect(db_path) as conn:
print(f"Writing data to table '{table_name}' using strategy '{if_exists}'...")
# Write data to the SQLite table
df.to_sql(name=table_name,
con=conn,
if_exists=if_exists,
index=False)
print(f"Successfully loaded data into table '{table_name}' in database '{db_path}'.")
# Optional: Verify by counting rows in the new table
cursor = conn.cursor()
cursor.execute(f"SELECT COUNT(*) FROM {table_name}")
count = cursor.fetchone()[0]
print(f"Verification: Table '{table_name}' now contains {count} rows.")
except sqlite3.Error as e:
print(f"SQLite error occurred: {e}")
except Exception as e:
print(f"An unexpected error occurred during database operation: {e}")
Explanation:
- Configuration: Sets paths for the input CSV, output database, table name, and how to handle existing tables (
replaceis good for full refreshes). load_csv_to_sqlitefunction:- Reads the specified CSV file into a Pandas DataFrame.
- Includes basic error handling for file existence and empty files.
- Connects to the SQLite database (it will create
data.sqliteif it doesn’t exist). - Uses the powerful
df.to_sql()method from Pandas to directly write the DataFrame’s content into an SQL table.if_exists='replace': If the tabledashboard_dataalready exists, it will be dropped and recreated. Other options are'append'(add new data) or'fail'(raise an error).index=False: Prevents Pandas from writing the DataFrame’s numerical index as a column in the SQL table.
- Prints status messages and a verification count.
I am usign this script just to create the demo database. You would typically run this script once to set up your database or whenever your sales-data.csv is updated.
utils.py: Essential Helper Functions
This file centralizes common operations used by the AI Agent for BI.
# utils.py
import sqlite3
import base64
import os
import glob
from PIL import Image
from io import BytesIO
import pandas as pd
DATABASE_PATH = "data.sqlite"
DASHBOARD_IMAGE_FOLDER = "dashboard"
def get_db_connection():
"""Establishes a connection to the SQLite database."""
try:
conn = sqlite3.connect(DATABASE_PATH)
return conn
except sqlite3.Error as e:
print(f"Error connecting to database: {e}")
return None
def get_db_schema(conn):
"""Retrieves the schema of the database."""
try:
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
schema = {}
for table_name in tables:
table_name = table_name[0]
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
schema[table_name] = [(col[1], col[2]) for col in columns] # name, type
return schema
except sqlite3.Error as e:
print(f"Error retrieving schema: {e}")
return None
finally:
# Keep connection open for potential queries within the agent run
pass
def execute_sql(conn, query):
"""Executes a SQL query and returns the results as a Pandas DataFrame."""
try:
df = pd.read_sql_query(query, conn)
# Limit results for brevity in LLM context if necessary
if len(df) > 100:
df_head = df.head(50).to_string()
df_tail = df.tail(50).to_string()
return f"Executed query: {query}\nResult (showing first 50 and last 50 rows out of {len(df)}):\n{df_head}\n...\n{df_tail}"
else:
return f"Executed query: {query}\nResult:\n{df.to_string()}"
except (sqlite3.Error, pd.io.sql.DatabaseError) as e:
print(f"Error executing SQL: {e}")
return f"Error executing SQL: {e}\nQuery: {query}"
except Exception as e:
print(f"An unexpected error occurred during SQL execution: {e}")
return f"An unexpected error occurred during SQL execution: {e}\nQuery: {query}"
def encode_image(image_path, max_size=(1024, 1024)):
"""Encodes an image file to a base64 string, resizing if needed."""
try:
with Image.open(image_path) as img:
# Convert RGBA to RGB if necessary
if img.mode == 'RGBA':
img = img.convert('RGB')
img.thumbnail(max_size) # Resize while preserving aspect ratio
buffered = BytesIO()
img.save(buffered, format="JPEG") # Save as JPEG
return base64.b64encode(buffered.getvalue()).decode('utf-8')
except Exception as e:
print(f"Error encoding image {image_path}: {e}")
return None
def load_dashboard_images(folder_path):
"""Loads and encodes all PNG images from a folder."""
images = []
image_files = glob.glob(os.path.join(folder_path, "*.png"))
if not image_files:
print(f"Warning: No PNG images found in folder: {folder_path}")
for image_path in image_files:
encoded_image = encode_image(image_path)
if encoded_image:
images.append({
"filename": os.path.basename(image_path),
"base64": encoded_image
})
return imagesExplanation:
get_db_connection(): A simple wrapper to connect to the SQLite database defined byDATABASE_PATH.get_db_schema(conn): This is crucial. It inspects the database and extracts the names of all tables and, for each table, the names and data types of its columns. This schema information is provided to the LLM so it knows what tables and columns are available when it generates SQL queries.execute_sql(conn, query): Takes a database connection and an SQL query string. It usespd.read_sql_queryto execute the query and fetch results into a Pandas DataFrame. For brevity in LLM prompts, if the result set is large, it returns a string representation of only the head and tail. It also includes error handling and returns the error message if the SQL execution fails.encode_image(image_path, max_size): This function is vital for the multimodal capability. It opens an image using Pillow, converts it to RGB (JPEG format doesn’t support transparency/alpha channels found in some PNGs), resizes it (usingthumbnailto maintain aspect ratio and limit size for LLM token efficiency), saves it to an in-memory buffer as a JPEG, and then encodes this JPEG image data into a Base64 string. Base64 is a way to represent binary data as text, which can then be easily included in JSON payloads or prompts for the LLM.load_dashboard_images(folder_path): Usesglobto find all.pngfiles in theDASHBOARD_IMAGE_FOLDER. For each image, it callsencode_imageand stores the filename and its Base64 encoded string in a list of dictionaries. This list is then passed to the agent.
main.py: The Agent’s Brain
This is where the magic happens, orchestrating the LLM and the various steps using LangGraph.
# main.py
import os
import sys
import pandas as pd
import sqlite3
from dotenv import load_dotenv
from typing import TypedDict, List, Dict, Optional, Annotated
import operator # For graph state updates
# Langchain specific imports
from langchain_openai import ChatOpenAI
from langchain_google_vertexai import ChatVertexAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# from langchain_core.pydantic_v1 import BaseModel, Field
from pydantic import BaseModel, Field
# Langgraph imports
from langgraph.graph import StateGraph, END
# LangSmith imports
from langsmith import traceable
# --- AI Agent for BI State Definition ---
class AgentState(TypedDict):
user_question: str
dashboard_images: List[Dict[str, str]] # List of {"filename": str, "base64": str}
db_schema: Dict # Dictionary describing tables and columns
identified_chart_filename: Optional[str]
required_data_description: Optional[str]
needs_clarification: bool
clarification_message: Optional[str]
sql_query: Optional[str]
db_results: Optional[str]
final_answer: Optional[str]
error_message: Optional[str]
# --- LLM Initialization ---
# To use OpenAI
# llm = ChatOpenAI(model="gpt-4o", temperature=0)
# To use Gemini
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()
llm = ChatVertexAI(
model="gemini-2.5-pro-preview-03-25",
project=GOOGLE_PROJECT_ID,
location=REGION,
temperature=0,
max_tokens=None,
max_retries=6,
stop=None,
)
# --- Pydantic Models for Structured Output ---
class ChartIdentificationResult(BaseModel):
"""Structure to hold the identified chart and data requirements."""
relevant_chart_filename: Optional[str] = Field(..., description="The filename of the most relevant chart (e.g., 'chart1_sales_trend.png'). Set to null if unclear or not applicable.")
data_needed_description: Optional[str] = Field(..., description="A natural language description of the specific data (metrics, dimensions, filters like time periods or categories mentioned/implied by the question) needed from the database to answer the user's question, considering the context of the identified chart. Set to null if unclear.")
is_clarification_needed: bool = Field(..., description="Set to true if either the relevant chart or the required data needed to answer the question is unclear, otherwise false.")
class SQLQuery(BaseModel):
"""A SQL query designed to fetch data relevant to a user question about a specific chart."""
query: str = Field(..., description="A valid SQLite query.")
# --- Node Functions ---
def identify_chart_and_data_needs_node(state: AgentState):
"""
Identifies the relevant chart AND determines the specific data needed
from the database to answer the user's question, using multimodal input.
"""
print("--- Node: identify_chart_and_data_needs ---")
user_question = state["user_question"]
images = state["dashboard_images"]
if not images:
print("Error: No dashboard images loaded.")
return {"error_message": "Dashboard images could not be loaded. Cannot proceed."}
image_messages = []
image_filenames = [img['filename'] for img in images]
for img in images:
image_messages.append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img['base64']}"}
})
prompt_text = f"""
You are an expert BI analyst assistant. Your task is to analyze a user's question about a set of dashboard charts and determine what information is needed to answer it.
User's Question:
"{user_question}"
Available Chart Images & Filenames:
{', '.join(image_filenames)}
(Images are attached)
Instructions:
1. Analyze the user's question.
2. Examine the attached chart images (titles, axes, data shown, chart type).
3. Identify the SINGLE most relevant chart filename that the user is likely asking about. If no single chart is clearly relevant, or the question is too generic, consider clarification needed.
4. Based on the user's question AND the content of the identified relevant chart, describe the SPECIFIC data needed from the underlying database to answer the question. This description should mention:
* Metrics (e.g., total sales, average revenue, count of products)
* Dimensions/Categories (e.g., by region, by product category, by month)
* Filters (e.g., for a specific time period like 'last quarter', for a specific region like 'North', for top N items)
5. Determine if you have enough information to proceed or if clarification is needed from the user (e.g., if the question is ambiguous, refers to multiple charts, or requires information not obviously present).
Output Format:
Provide your analysis in the specified structured format. Make sure `relevant_chart_filename` and `data_needed_description` are null if you determine clarification is needed. Set `is_clarification_needed` to true if you are uncertain about the chart OR the specific data required, otherwise set it to false.
"""
structured_llm = llm.with_structured_output(ChartIdentificationResult)
try:
response: ChartIdentificationResult = structured_llm.invoke([
HumanMessage(content=[
{"type": "text", "text": prompt_text},
*image_messages # Unpack the list of image dictionaries
])
])
print(f"LLM Identification Response:\n"
f" Chart: {response.relevant_chart_filename}\n"
f" Data Needs: {response.data_needed_description}\n"
f" Clarification Needed: {response.is_clarification_needed}")
# Check if LLM failed to identify (often returns empty strings or None)
if response.is_clarification_needed or not response.relevant_chart_filename or not response.data_needed_description:
print("LLM indicated clarification is needed or failed to provide required info.")
# Ensure consistency if clarification is needed
return {
"needs_clarification": True,
"identified_chart_filename": None,
"required_data_description": None
}
else:
# Check if the identified filename is valid
if response.relevant_chart_filename not in image_filenames:
print(f"Warning: LLM identified a non-existent chart filename '{response.relevant_chart_filename}'. Requesting clarification.")
return {
"needs_clarification": True,
"identified_chart_filename": None,
"required_data_description": None
}
else:
# Success case
return {
"needs_clarification": False,
"identified_chart_filename": response.relevant_chart_filename,
"required_data_description": response.data_needed_description
}
except Exception as e:
print(f"Error during chart identification and data needs analysis: {e}")
# Fallback to needing clarification on error
return {
"needs_clarification": True,
"identified_chart_filename": None,
"required_data_description": None,
"error_message": f"An error occurred during analysis: {e}" # Optionally pass error
}
def generate_clarification_node(state: AgentState):
"""Generates a message asking the user for clarification."""
print("--- Node: generate_clarification ---")
user_question = state["user_question"]
image_filenames = [img['filename'] for img in state["dashboard_images"]]
# Generic clarification prompt
prompt = f"""
You are a helpful assistant. The user asked the following question about a BI dashboard:
"{user_question}"
You need more information or clarity to proceed. This could be because the relevant chart is unclear, or the specific data required (like time periods or categories) is ambiguous. The available charts are:
{', '.join(image_filenames)}
Please formulate a polite question asking the user to clarify their request. Ask them to specify the chart if it's unclear, or provide more details about what they want to know (e.g., time range, specific region/product).
Example: "Could you please specify which chart you're asking about (e.g., '{image_filenames[0]}')? Also, could you clarify the time period or specific categories you're interested in?"
"""
try:
response = llm.invoke([HumanMessage(content=prompt)])
clarification_msg = response.content
print(f"Generated clarification: {clarification_msg}")
# Stop here in this version. A production chatbot would send this and wait.
return {"clarification_message": clarification_msg}
except Exception as e:
print(f"Error generating clarification: {e}")
return {"error_message": f"Failed to generate clarification message: {e}"}
def generate_sql_node(state: AgentState):
"""Generates an SQL query based on the data description, user question, chart, and schema."""
print("--- Node: generate_sql ---")
user_question = state["user_question"]
chart_filename = state["identified_chart_filename"]
data_description = state["required_data_description"]
db_schema = state["db_schema"]
# Guard clauses
if not chart_filename:
return {"error_message": "Cannot generate SQL without an identified chart."}
if not data_description:
return {"error_message": "Cannot generate SQL without a description of the required data."}
if not db_schema:
return {"error_message": "Cannot generate SQL without database schema."}
# Find the specific image data for visual context (optional but helpful)
chart_image_b64 = next((img["base64"] for img in state["dashboard_images"] if img["filename"] == chart_filename), None)
# Prepare prompt content
prompt_messages = [
SystemMessage(content="You are an expert SQL generator. Your task is to create a precise SQLite query to fetch data needed to answer a user's question about a specific BI chart, based on a description of the required data and the database schema."),
HumanMessage(content=f"""
Database Schema:
```json
{db_schema}
```
User Question:
"{user_question}"
Relevant Chart:
"{chart_filename}"
Required Data Description (derived from question and chart context):
"{data_description}"
Task: Generate a single, valid SQLite query that retrieves the specific data described above ('Required Data Description') from the database (using the provided 'Database Schema') to answer the 'User Question' in the context of the 'Relevant Chart'.
Guidelines:
- Adhere strictly to the 'Required Data Description' for selecting columns, applying filters (WHERE clauses), and using aggregations (SUM, AVG, COUNT, etc.).
- Ensure the query is valid SQLite syntax.
- Select only necessary columns. Avoid `SELECT *`.
- Be precise with filters (dates, categories, regions, etc.) as specified in the data description.
- Consider the chart type implied by '{chart_filename}' when interpreting the data description (e.g., trends need time series data, regional maps need geographical data).
- Respond ONLY with the SQL query itself. No explanations, introductions, or markdown formatting like ```sql.
"""),
]
# Add the specific chart image if available for visual context
if chart_image_b64:
prompt_messages.insert(1, HumanMessage(content=[ # Insert between System and main Human message
{"type": "text", "text": f"Visual context for chart '{chart_filename}':"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{chart_image_b64}"}}
]))
# Use structured output to enforce SQL format
structured_llm_sql = llm.with_structured_output(SQLQuery)
try:
response = structured_llm_sql.invoke(prompt_messages) # With structured output
sql_query = response.query.strip() # Ensure no leading/trailing whitespace
# Basic validation (can be expanded)
if not sql_query.upper().startswith("SELECT"):
print(f"Warning: Generated query doesn't start with SELECT: {sql_query}. Attempting to use anyway.")
# Or raise error
print(f"Generated SQL: {sql_query}")
return {"sql_query": sql_query}
except Exception as e:
print(f"Error generating SQL: {e}")
error_detail = str(e)
return {"error_message": f"Failed to generate SQL query: {error_detail}"}
def execute_sql_node(state: AgentState):
"""Executes the generated SQL query against the database."""
print("--- Node: execute_sql ---")
sql_query = state["sql_query"]
if not sql_query:
# Handle case where SQL generation failed but graph proceeded
error_msg = state.get("error_message", "No SQL query provided to execute.")
print(f"Skipping SQL execution: {error_msg}")
return {"error_message": error_msg, "db_results": None}
conn = None
try:
conn = get_db_connection()
if conn:
results = execute_sql(conn, sql_query)
print(f"SQL Execution Results (preview): {str(results)[:500]}...")
# Check if execute_sql returned an error string
if isinstance(results, str) and results.lower().startswith("error"):
print(f"SQL execution failed: {results}")
return {"db_results": None, "error_message": results} # Propagate DB error
else:
return {"db_results": results}
else:
err_msg = "Failed to establish database connection."
print(f"Error: {err_msg}")
return {"error_message": err_msg}
except Exception as e:
# Catch unexpected errors during connection or execution call
err_msg = f"An unexpected error occurred during SQL execution node: {e}"
print(err_msg)
return {"error_message": err_msg}
finally:
if conn:
try:
conn.close()
print("Database connection closed.")
except Exception as e:
print(f"Error closing database connection: {e}")
def analyze_results_node(state: AgentState):
"""Analyzes the SQL results and generates a final natural language answer."""
print("--- Node: analyze_results ---")
user_question = state["user_question"]
chart_filename = state["identified_chart_filename"] # Still useful for context
sql_query = state["sql_query"]
db_results = state["db_results"]
upstream_error = state.get("error_message")
# If an error occurred in previous steps (like SQL execution), handle it.
if upstream_error and db_results is None:
print(f"Skipping analysis due to upstream error: {upstream_error}")
# Provide a user-friendly message indicating the failure point
final_answer = f"Sorry, I couldn't answer your question. I encountered an issue retrieving or processing the data needed. Error: {upstream_error}"
return {"final_answer": final_answer}
# Handle case where SQL executed but returned no results or helper formatted it as error
if db_results is None:
err_msg = "No data was returned from the database for your query."
print(f"Error: {err_msg}")
final_answer = f"I executed the query, but it returned no results. This might mean there's no data matching your criteria.\nQuery Attempted: ```sql\n{sql_query}\n```"
# Update error message in state if needed, although we provide a final answer
return {"final_answer": final_answer, "error_message": err_msg}
# Find the specific image data for context
chart_image_b64 = next((img["base64"] for img in state["dashboard_images"] if img["filename"] == chart_filename), None)
prompt_messages = [
SystemMessage(content="You are a helpful BI analyst assistant. Your goal is to provide clear, concise, and accurate answers to user questions based on retrieved database data, relating it back to the relevant dashboard chart."),
HumanMessage(content=f"""
Context:
- User's Question: "{user_question}"
- Relevant Chart: '{chart_filename}' (visual context provided if available)
- Query Executed:
```sql
{sql_query}
```
- Data Retrieved:
```
{db_results}
```
Task:
Analyze the 'Data Retrieved' in the context of the 'User's Question' and the 'Relevant Chart'. Provide a natural language answer that directly addresses the question using insights derived from the data.
Guidelines:
- Be direct and answer the question clearly.
- Summarize key findings from the data. Do not just repeat the raw data table.
- If the data seems insufficient to fully answer, state that politely.
- Relate the findings back to the likely purpose or display of the chart '{chart_filename}' if appropriate (e.g., "As the sales trend chart shows...").
- Keep the language accessible and professional.
"""),
]
# Add the specific chart image if available
if chart_image_b64:
prompt_messages.insert(1, HumanMessage(content=[
{"type": "text", "text": f"Visual context for chart '{chart_filename}':"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{chart_image_b64}"}}
]))
try:
response = llm.invoke(prompt_messages)
final_answer = response.content
print(f"Generated Final Answer: {final_answer}")
return {"final_answer": final_answer}
except Exception as e:
print(f"Error during final analysis: {e}")
# Provide data if analysis fails, but explain the issue
error_answer = f"I retrieved the data successfully, but encountered an issue while analyzing it to formulate the final answer. Error: {e}\n\nHere is the raw data retrieved:\n{db_results}"
return {"final_answer": error_answer}
# --- Conditional Edge Logic ---
def decide_next_step(state: AgentState):
"""Determines the next step based on whether clarification is needed."""
print("--- Decision: decide_next_step ---")
# Prioritize checking for upstream errors that might have occurred in the identification node
if state.get("error_message") and not state.get("final_answer"): # Check if error happened before final answer attempt
print(f"Routing to: END (due to error: {state.get('error_message')})")
return END
# Check the flag set by the identification node
if state["needs_clarification"]:
print("Routing to: generate_clarification")
return "generate_clarification"
elif state["identified_chart_filename"] and state["required_data_description"]:
# Proceed only if we have both chart and data needs identified
print("Routing to: generate_sql")
return "generate_sql"
else:
# This case might happen if identification fails unexpectedly without setting needs_clarification=True
print("Routing to: END (unexpected state: clarification not needed, but chart/data info missing)")
# Optionally set an error message here
state["error_message"] = "Agent reached an inconsistent state after chart identification."
return END
# --- Build the Graph ---
def build_agent_graph():
"""Builds the LangGraph agent."""
workflow = StateGraph(AgentState)
# Add nodes
workflow.add_node("identify_chart_and_data_needs", identify_chart_and_data_needs_node)
workflow.add_node("generate_clarification", generate_clarification_node)
workflow.add_node("generate_sql", generate_sql_node)
workflow.add_node("execute_sql", execute_sql_node)
workflow.add_node("analyze_results", analyze_results_node)
# Set entry point
workflow.set_entry_point("identify_chart_and_data_needs")
# Add conditional edges from the identification node
workflow.add_conditional_edges(
"identify_chart_and_data_needs",
decide_next_step,
{
"generate_clarification": "generate_clarification",
"generate_sql": "generate_sql",
END: END # Handle direct END route from decision logic (errors or unexpected state)
}
)
# Add sequential edges for the main flow
workflow.add_edge("generate_sql", "execute_sql")
workflow.add_edge("execute_sql", "analyze_results")
# Define end points for paths
workflow.add_edge("generate_clarification", END) # Clarification path ends here
workflow.add_edge("analyze_results", END) # Successful analysis path ends here
# Compile the graph
app = workflow.compile()
return app
Explanation of main.py:
AgentState(TypedDict): This dictionary defines the “memory” or state of our AI Agent for BI. It holds all pieces of information that are passed between different steps (nodes) in our graph, such as the user’s question, loaded dashboard images (base64 encoded), database schema, intermediate findings (like the identified chart or generated SQL), and the final answer or any errors.- LLM Initialization (
ChatVertexAI): Sets up the connection to the Gemini Pro model via Vertex AI.temperature=0is used to make the output more deterministic and less random, which is usually preferred for analytical tasks. - Pydantic Models (
ChartIdentificationResult,SQLQuery): These define the expected structure for specific LLM outputs. For instance, when asking the LLM to identify a chart and data needs, we tell it to respond in theChartIdentificationResultformat. Langchain then automatically parses the LLM’s JSON output into these model objects, making it easy and safe to access the data (e.g.,response.relevant_chart_filename). - Node Functions: These are the building blocks of our agent’s workflow, defined as Python functions. Each node performs a specific task:
identify_chart_and_data_needs_node: This is the crucial first step.- It receives the
user_questionand thedashboard_images(with their base64 data). - It constructs a detailed prompt asking the multimodal LLM to:
- Look at all the provided chart images.
- Understand the user’s question.
- Identify which specific chart image filename is most relevant to the question.
- Describe, in natural language, what specific data (metrics, dimensions, filters like time periods or categories) would be needed from the database to answer the question, considering the context of the identified chart.
- Determine if the question is ambiguous or lacks detail, thus requiring clarification from the user.
- The prompt includes the text of the question and the actual image data (as
image_urlwith base64 strings). - It uses
llm.with_structured_output(ChartIdentificationResult)to ensure the LLM’s response conforms to our Pydantic model. - It updates the
AgentStatewithidentified_chart_filename,required_data_description, and a booleanneeds_clarification.
- It receives the
generate_clarification_node: If the previous node setsneeds_clarificationtoTrue, this node is called. It simply prompts the LLM to generate a polite question to ask the user for more details.generate_sql_node: If clarification is not needed, this node takes theuser_question, theidentified_chart_filename, therequired_data_description(from the identification node), and thedb_schema.- It constructs a prompt instructing the LLM to act as an SQL expert.
- It provides the database schema (so the LLM knows table and column names).
- It provides the natural language description of the data needed.
- It may also provide the specific image of the identified chart for additional visual context to help the LLM write a more accurate query.
- It uses
llm.with_structured_output(SQLQuery)to get a clean SQL query.
execute_sql_node: This node takes thesql_querygenerated by the previous node. It uses theget_db_connection()andexecute_sql()utility functions to run the query againstdata.sqliteand fetches the results.analyze_results_node: This final analytical node takes theuser_question,sql_query, and thedb_results.- It prompts the LLM to synthesize the retrieved data into a natural language answer that directly addresses the user’s original question, relating it back to the identified chart if possible.
- It may also provide the specific image of the identified chart again, so the LLM can refer to it when formulating the answer (e.g., “As you can see in the
sales_dashboard.pngchart…”).
- Conditional Edge Logic (
decide_next_step): This function is a key part of LangGraph. After theidentify_chart_and_data_needs_noderuns, this function is called to determine where to go next:- If
needs_clarificationisTrue, it routes togenerate_clarification_node. - If everything is clear, it routes to
generate_sql_node. - If there’s an unrecoverable error, it can route to
END.
- If
- Building the Graph (
build_agent_graph):- A
StateGraphis initialized with ourAgentState. - Each node function is added to the graph with a unique name.
- The
set_entry_point()defines where the graph execution begins (identify_chart_and_data_needs). add_conditional_edges()connectsidentify_chart_and_data_needsto other nodes based on the output ofdecide_next_step.add_edge()defines sequential transitions (e.g., aftergenerate_sqlalways comesexecute_sql).- Nodes like
generate_clarificationandanalyze_resultslead toEND, signifying the completion of a path. - The graph is then
compile()d into a runnable application. - The graph can be visualized (as seen in your provided
agent_graph.png).
- A
- Preparation & Main Interaction Loop (
if __name__ == "__main__":)
The code executed inside the if __name__ == "__main__":
from langsmith import traceable
print("Loading dashboard images...")
dashboard_images = load_dashboard_images(DASHBOARD_IMAGE_FOLDER)
if not dashboard_images:
print(f"Error: Could not load any dashboard images from '{DASHBOARD_IMAGE_FOLDER}'. Exiting.")
exit(1)
print(f"Loaded {len(dashboard_images)} images: {[img['filename'] for img in dashboard_images]}")
print("Connecting to database and retrieving schema...")
db_schema = None
conn_temp = get_db_connection()
if conn_temp:
try:
db_schema = get_db_schema(conn_temp)
finally:
conn_temp.close()
if not db_schema:
print(f"Error: Could not retrieve database schema from '{DATABASE_PATH}'. Exiting.") # Use constant
exit(1)
print("Database schema loaded.")
# print(f"Schema: {db_schema}") # Print schema for debugging
# Build the graph
agent_app = build_agent_graph()
@traceable
def invoke_agent(initial_state):
return agent_app.invoke(initial_state)
# Visualize the graph (optional)
try:
from PIL import Image
img_data = agent_app.get_graph().draw_mermaid_png()
with open("agent_graph.png", "wb") as f:
f.write(img_data)
print("Graph visualization saved to agent_graph.png")
except Exception as e:
print(f"Could not draw graph: {e} (requires playwright and pygraphviz/mermaid)")- It first loads the dashboard images using
utils.load_dashboard_images(). - It then connects to the database and retrieves the schema using
utils.get_db_schema(). - It builds the agent application by calling
build_agent_graph(). - It enters a loop, prompting the user for a question.
- For each question, it initializes the
AgentStatewith the question, images, and schema. - Initializes Agent invocation function
invoke_agent(initial_state)that invokes the compiled LangGraph app:final_state = agent_app.invoke(initial_state). This runs the entire graph from the entry point until anENDstate is reached. - Finally, it creates a graph visualization and saves it to the local folder. This step is optional and can be commented out.
Lets look at the Agent workflow saved into the local folder:
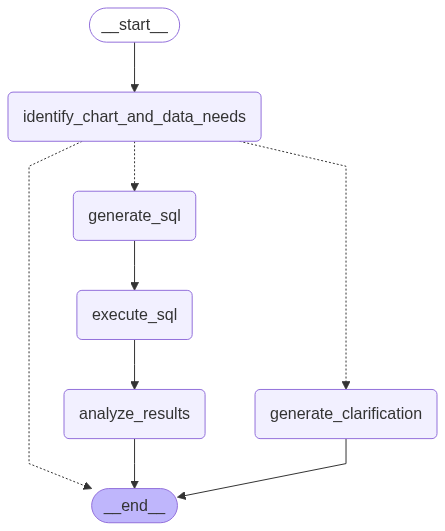


You can see that we are using LangSmith tracing (decorator @traceable on the Agent invocation function). I plan to dive deeper into LangSmith and its capabilities in one of the next articles.
AI Agent for BI in Action
Let’s look at how the AI Agent for BI handles some of your test questions.
I’ve downloaded the interactive sales dashboard Excel file from the Chandoo.org website.
From these files, I’ve pulled the raw sales data and saved it to a CSV file (later loaded to the data.sqlite database) and saved dashboard image:
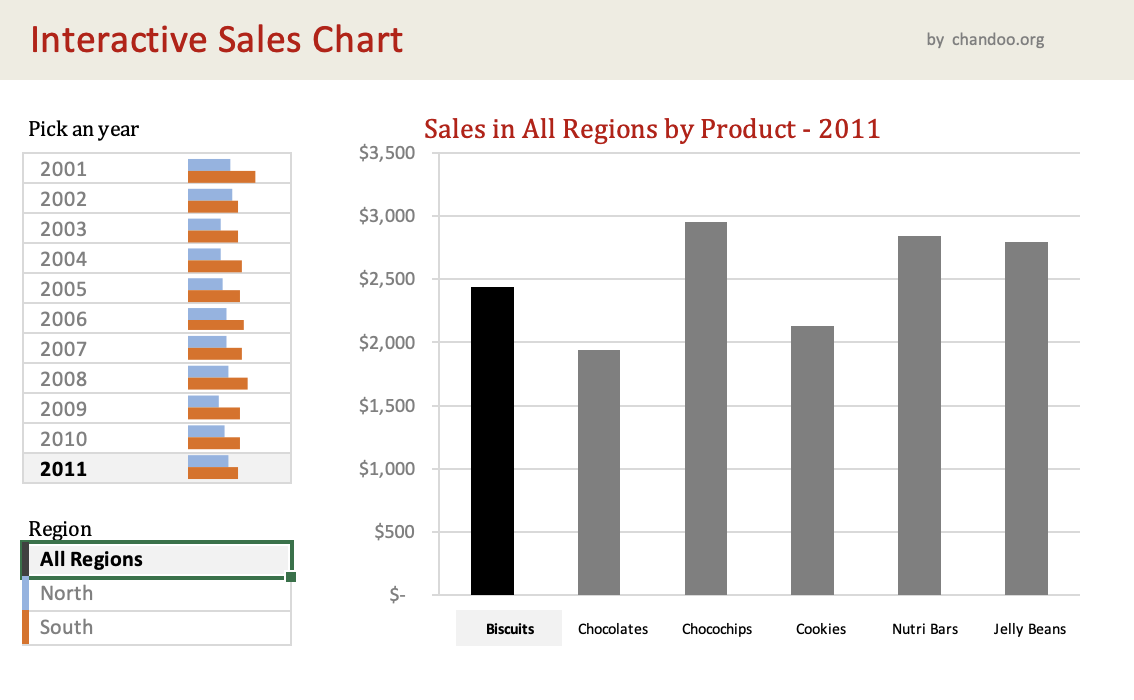
The dashboard shows “Interactive Sales Chart” with a “Pick an year” (I kept the original orphography to have a confusing element for the LLM) filter (2001-2011) on the left, a “Region” filter (All Regions, North, South), and a main bar chart “Sales in All Regions by Product – 2011” showing sales for Biscuits, Chocolates, Chocochips, Cookies, Nutri Bars, Jelly Beans.
Finally we can do some testing! Here are some questions that I’ve asked our AI Agent for BI:
- Which product(s) shows growth from 2003 to 2009 in combined north and south regions?
- This question would help uderstand how well the Agent can understand and explain the data.
- Which product has higher sales in 2010? In which region had this product has the highest sales that year?
- This question should help us understand how well the AI Agent for BI would combine the dashboard visual with data in the db.
- What does chart named Pick an year showing?
- This question should help us understand if our Agent would be able to localized the specific chart by a very fuzzy description. And if not, would it be able to clarify the question properly.
- What does chart in sales data dashboard with title Pick an year showing?
- This question would help us understand how well the AI Agent for BI expains the dashboard charts and if it would provide factuall data from the database to support the explanation. I know that the data is not full. Some of the years are missing, as I’ve only taken the part of the raw sales data.
Lets see if the Agent is going to tackle those questions.
— BI Dashboard Agent Ready —
Ask a question about the dashboard (or type ‘quit’ to exit): Which product(s) shows growth from 2003 to 2009 in combined north and south regions?
— Running Agent —
— Node: identify_chart_and_data_needs —
LLM Identification Response:
Chart: sales_dashboard.png
Data Needs: Total sales for each product in the North region for the year 2003, total sales for each product in the South region for the year 2003, total sales for each product in the North region for the year 2009, and total sales for each product in the South region for the year 2009. This data will be used to calculate the combined sales (North + South) for each product in 2003 and 2009, and then identify products that showed growth between these two periods.
Clarification Needed: False
— Decision: decide_next_step —
Routing to: generate_sql
— Node: generate_sql —
Generated SQL: SELECT Product, Year, Region, SUM(“Sales ($)”) FROM dashboard_data WHERE Year IN (2003, 2009) AND Region IN (‘North’, ‘South’) GROUP BY Product, Year, Region
— Node: execute_sql —
SQL Execution Results (preview): Executed query: SELECT Product, Year, Region, SUM(“Sales ($)”) FROM dashboard_data WHERE Year IN (2003, 2009) AND Region IN (‘North’, ‘South’) GROUP BY Product, Year, Region
Result:
Product Year Region SUM(“Sales ($)”)
0 Biscuits 2003 North 880
1 Biscuits 2003 South 1350
2 Biscuits 2009 North 850
3 Biscuits 2009 South 1390
4 Chocochips 2003 North 1140
5 Chocochips 2003 South …
Database connection closed.
— Node: analyze_results —
Generated Final Answer: Based on the data for the combined North and South regions:
* **Biscuits** sales grew from $2,230 in 2003 to $2,240 in 2009.
* **Chocochips** sales grew from $1,960 in 2003 to $2,340 in 2009.
* **Chocolates** sales grew from $2,100 in 2003 to $2,620 in 2009.
* **Cookies** sales grew from $2,570 in 2003 to $2,920 in 2009.
* **Jelly Beans** sales grew from $2,510 in 2003 to $2,580 in 2009.
**Nutri Bars** sales decreased from $2,790 in 2003 to $2,410 in 2009.
Therefore, Biscuits, Chocochips, Chocolates, Cookies, and Jelly Beans showed sales growth from 2003 to 2009 in the combined North and South regions.
While the ‘Interactive Sales Chart’ currently displays data for 2011, you could use its “Pick an year” and “Region” filters to visualize sales for individual products in 2003 and 2009 for “All Regions” (by selecting North and South, or if an “All Regions” option sums them) to see these trends, though a direct comparison between the two years isn’t shown in the provided static image.
— Agent Finished —
— Final Answer —
Based on the data for the combined North and South regions:
* **Biscuits** sales grew from $2,230 in 2003 to $2,240 in 2009.
* **Chocochips** sales grew from $1,960 in 2003 to $2,340 in 2009.
* **Chocolates** sales grew from $2,100 in 2003 to $2,620 in 2009.
* **Cookies** sales grew from $2,570 in 2003 to $2,920 in 2009.
* **Jelly Beans** sales grew from $2,510 in 2003 to $2,580 in 2009.
**Nutri Bars** sales decreased from $2,790 in 2003 to $2,410 in 2009.
Therefore, Biscuits, Chocochips, Chocolates, Cookies, and Jelly Beans showed sales growth from 2003 to 2009 in the combined North and South regions.
While the ‘Interactive Sales Chart’ currently displays data for 2011, you could use its “Pick an year” and “Region” filters to visualize sales for individual products in 2003 and 2009 for “All Regions” (by selecting North and South, or if an “All Regions” option sums them) to see these trends, though a direct comparison between the two years isn’t shown in the provided static image.
Not bad, right? AI Agent for BI provided the answer, supported by the data. It also explained user how they could get some of the information by applying filter. Let’s move on to the next question:
————————————————–
Ask a question about the dashboard (or type ‘quit’ to exit): Which product has higher sales in 2010? In which region had this product has the highest sales that year?
— Running Agent —
— Node: identify_chart_and_data_needs —
LLM Identification Response:
Chart: sales_dashboard.png
Data Needs: Total sales by product and by region for the year 2010. This will be used to first identify the product with the highest sales in 2010, and then to find the region where that specific product had the highest sales in 2010.
Clarification Needed: False
— Decision: decide_next_step —
Routing to: generate_sql
— Node: generate_sql —
Generated SQL: SELECT Product, Region, SUM(“Sales ($)”) FROM dashboard_data WHERE Year = 2010 GROUP BY Product, Region
— Node: execute_sql —
SQL Execution Results (preview): Executed query: SELECT Product, Region, SUM(“Sales ($)”) FROM dashboard_data WHERE Year = 2010 GROUP BY Product, Region
Result:
Product Region SUM(“Sales ($)”)
0 Biscuits North 1010
1 Biscuits South 1420
2 Chocochips North 1100
3 Chocochips South 1360
4 Chocolates North 970
5 Chocolates South 1370
6 Cookies North 1120
7 Cookies South 1380
8 …
Database connection closed.
— Node: analyze_results —
Generated Final Answer: In 2010, Jelly Beans had the highest sales, totaling $3,230. This product achieved its highest sales in the South region, with $2,100.
While the ‘Interactive Sales Chart’ currently displays data for 2011, if you were to select the year 2010, the bar chart would reflect Jelly Beans as the top-selling product, with its sales predominantly coming from the South region.
— Agent Finished —
— Final Answer —
In 2010, Jelly Beans had the highest sales, totaling $3,230. This product achieved its highest sales in the South region, with $2,100.
While the ‘Interactive Sales Chart’ currently displays data for 2011, if you were to select the year 2010, the bar chart would reflect Jelly Beans as the top-selling product, with its sales predominantly coming from the South region.
AI Agent for BI got the data, combined with visuals and answered the user.
Moving on:
————————————————–
Ask a question about the dashboard (or type ‘quit’ to exit): What does chart named Pick an year showing?
— Running Agent —
— Node: identify_chart_and_data_needs —
LLM Identification Response:
Chart: sales_dashboard.png
Data Needs: The ‘Pick an year’ section on the chart ‘sales_dashboard.png’ displays two distinct horizontal bars (one light blue, one orange) for each year from 2001 to 2011. To explain what this section is showing, clarification is needed on what these two different bars represent for each year (e.g., are they different metrics, or actual vs. target values for a single metric?).
Clarification Needed: True
LLM indicated clarification is needed or failed to provide required info.
— Decision: decide_next_step —
Routing to: generate_clarification
— Node: generate_clarification —
Generated clarification: I understand you’re asking about an element named ‘Pick an year’ on the `sales_dashboard.png`. To help clarify what this element is showing, could you please tell me:
* Is ‘Pick an year’ the title of a specific chart, or is it an interactive feature like a dropdown menu for selecting a year?
* If it is a chart, what specific information are you interested in? For example, are you looking for data related to a particular year that might be selected, or are you interested in the general types of metrics it displays (such as sales, growth, etc.) once a year is chosen?
— Agent Finished —
— Clarification Needed —
I understand you’re asking about an element named ‘Pick an year’ on the `sales_dashboard.png`. To help clarify what this element is showing, could you please tell me:
* Is ‘Pick an year’ the title of a specific chart, or is it an interactive feature like a dropdown menu for selecting a year?
* If it is a chart, what specific information are you interested in? For example, are you looking for data related to a particular year that might be selected, or are you interested in the general types of metrics it displays (such as sales, growth, etc.) once a year is chosen?
The Agent was confused and asked for the clarifications. Lets try now the less ambiguously formulated version of the question:
————————————————–
Ask a question about the dashboard (or type ‘quit’ to exit): What does chart in sales data dashboard with title Pick an year showing?
— Running Agent —
— Node: identify_chart_and_data_needs —
LLM Identification Response:
Chart: sales_dashboard.png
Data Needs: Sales amount for each product. The data needs to be filtered for the specific year selected by the ‘Pick an year’ control (the image shows 2011 selected and reflected in the chart title ‘Sales in All Regions by Product – 2011’) and for the specific region selected by the ‘Region’ control (the image shows ‘All Regions’ selected).
Clarification Needed: False
— Decision: decide_next_step —
Routing to: generate_sql
— Node: generate_sql —
Generated SQL: SELECT Product, SUM(“Sales ($)”) FROM dashboard_data WHERE Year = 2011 AND Region = “All Regions” GROUP BY Product
— Node: execute_sql —
SQL Execution Results (preview): Executed query: SELECT Product, SUM(“Sales ($)”) FROM dashboard_data WHERE Year = 2011 AND Region = “All Regions” GROUP BY Product
Result:
Empty DataFrame
Columns: [Product, SUM(“Sales ($)”)]
Index: []…
Database connection closed.
— Node: analyze_results —
Generated Final Answer: The section labeled ‘Pick an year’ on the sales dashboard lists the years 2001 through 2011. Each year in this list is accompanied by a small horizontal bar chart. These mini-charts visually represent a key metric, most likely total sales, for their respective year, allowing for a quick comparison of annual performance. This entire section serves as an interactive filter: selecting a year (like 2011, which is currently highlighted in the image) updates the main ‘Sales in All Regions by Product’ chart to display data for that specific year.
Regarding the retrieved data, the database query was executed to fetch the product sales breakdown for the year 2011 (the currently selected year) for the main chart. However, this query returned no data. This outcome is inconsistent with the visual information in the ‘sales_dashboard.png’ image, where the main chart clearly displays sales figures for various products (Biscuits, Chocolates, etc.) for the year 2011. This discrepancy suggests that the provided query result might not reflect the data actually populating the visible dashboard, or there could be an issue in the data retrieval step that led to an empty dataset for the main chart’s content.
— Agent Finished —
— Final Answer —
The section labeled ‘Pick an year’ on the sales dashboard lists the years 2001 through 2011. Each year in this list is accompanied by a small horizontal bar chart. These mini-charts visually represent a key metric, most likely total sales, for their respective year, allowing for a quick comparison of annual performance. This entire section serves as an interactive filter: selecting a year (like 2011, which is currently highlighted in the image) updates the main ‘Sales in All Regions by Product’ chart to display data for that specific year.
Regarding the retrieved data, the database query was executed to fetch the product sales breakdown for the year 2011 (the currently selected year) for the main chart. However, this query returned no data. This outcome is inconsistent with the visual information in the ‘sales_dashboard.png’ image, where the main chart clearly displays sales figures for various products (Biscuits, Chocolates, etc.) for the year 2011. This discrepancy suggests that the provided query result might not reflect the data actually populating the visible dashboard, or there could be an issue in the data retrieval step that led to an empty dataset for the main chart’s content.
————————————————–
Ask a question about the dashboard (or type ‘quit’ to exit): quit
Great! The Agent had been able to understand the request, provide the answer and check if the data exists in the database.
I encourage you to play more with the AI Agent for BI to see what can be improved and how it can be used.
Conclusion
We’ve journeyed through the creation of a conversational AI Agent for BI, a tool that transforms how users interact with their data. By combining the visual understanding of multimodal LLMs with the data retrieval power of SQL and the orchestration capabilities of LangGraph, we’ve built an assistant that can:
- See and understand dashboard charts.
- Comprehend natural language questions.
- Reason about what data is needed.
- Query databases directly.
- Deliver clear, actionable insights.
This approach makes BI more accessible, efficient, and powerful. It empowers users of all technical levels to explore data deeply and get answers to their most pressing business questions quickly.
Someof the Possible Applications are:
- Embedded BI Assistants: Integrating directly into existing BI platforms and tools.
- Data-Aware Chatbots: For customer service or internal helpdesks, capable of querying structured enterprise data.
- Voice-Activated Data Analysis: Allowing executives to query dashboards hands-free.
- Personalized Data Companions: Tailored assistants for specific roles (e.g., sales managers, marketing analysts) that understand their common queries and data needs.
Next Steps and Future Enhancements:
The journey doesn’t end here. This foundation can be expanded with more advanced features:
- More Sophisticated Error Handling & Self-Correction: Enabling the agent to retry queries or rephrase its understanding if initial attempts fail.
- Learning from User Feedback: Incorporating a mechanism for users to rate answers or provide corrections, allowing the agent to improve over time.
- Proactive Insights: Training the agent to identify trends, anomalies, or interesting correlations in the data and proactively offer them to the user.
- Multi-Turn Conversations: Allowing for more complex, iterative dialogues where the agent remembers previous interactions and context.
- Cross-Chart Analysis: Answering questions that require synthesizing information from multiple dashboard charts.
- New Visualization Generation: Enabling users to ask the agent to “show me a trend line for X” and have it generate a simple chart.
- Caching & Performance Optimization: For frequently asked questions or common data lookups.
- Enhanced Security & Permissions: Integrating with existing authentication systems to ensure users only access data they are authorized to see.
The AI Agent for BI we created demonstrates the exciting potential at the intersection of multimodal AI, data analytics, and natural language processing.
As these technologies continue to evolve, we can expect even more intuitive and intelligent ways to unlock the stories hidden within our data.
Start building, start experimenting, and bring your dashboards to life!
Frequently Asked Questions
What is a conversational AI Agent for BI?
A conversational BI agent is an AI-powered assistant that allows users to ask questions about their business intelligence dashboards in plain English. It understands the user’s query, analyzes both the visual charts and the underlying data, and provides a direct, natural language answer.
How can an AI agent “see” a dashboard?
The agent uses a multimodal Large Language Model (like Google’s Gemini or OpenAI’s GPT-4o). These models can process and understand information from both text and images simultaneously. By providing the model with images of the dashboard charts, it can analyze the titles, axes, and data trends to understand the visual context of a user’s question.
Does the agent only use the data visible on the chart?
No, and that is its key advantage. The agent uses the chart image for context but has the ability to generate and execute its own SQL queries against the full, underlying database. This allows it to answer questions that go beyond the pre-aggregated data shown on the dashboard, such as calculating trends over different time periods or finding specific data points.
What is LangGraph and why is it used here?
LangGraph is a library for building stateful, multi-step AI applications. It’s used to define the agent’s workflow as a graph of nodes (actions) and edges (transitions). This allows the agent to make decisions, such as whether to ask for clarification, generate an SQL query, or synthesize a final answer, creating a more robust and intelligent system than a simple, linear chain.

