
How to Predict the Future of AI
- Focus on First Principles: Stop chasing daily headlines. Instead, understand the fundamental engineering and economic drivers that cause technological leaps.
- Tools Shape the Work: The development of frameworks like PyTorch (built for research) and TensorFlow (built for production) predicted where the next architectural breakthroughs would come from.
- Scaling Creates Centralization: The immense cost of scaling Large Language Models (LLMs) in terms of data, architecture, and compute made the rise of well-funded labs like OpenAI inevitable.
- From Thinking to Doing: The current focus on AI Agents is the logical next step after achieving powerful reasoning and multimodal models. The next frontier is giving these agents the ability to act.
It seems like every day there’s a new AI model, a new breakthrough, a new “game-changing” technology that we’re all supposed to immediately understand. I hear from so many engineers, managers, and even founders that it feels impossible to keep up. The feeling is valid, but the premise is flawed.
The progress of AI isn’t chaos. It’s a story of cause and effect, a logical chain of innovations building one upon the other. If you stop chasing the headlines and instead focus on the first principles of how these systems are built, you can not only understand the present but also develop a strong intuition for what comes next.
After 15+ years of building and leading ML teams, I’ve found that this foundational perspective is the key to navigating the field with confidence. Let’s walk through the last decade to see how, at each step, the future was hiding in plain sight, driven by engineering realities and economic constraints.
I hope this detailed breakdown helps you see the forest for the trees.
Chapter 1: The Pre-Framework Era (Before 2015): A Sleeping Giant
Before 2015, Neural Networks were a powerful, yet largely academic, pursuit. For most people, two major hurdles kept NNs out of reach:
- Extreme Computational Cost: Training early models like the one in Google’s 2012 “cat paper” required massive, inaccessible clusters of 16,000 CPU cores.
- High Implementation Barrier: Building a neural network meant writing and debugging everything from scratch in languages like C++—including matrix operations, activation functions, and the notoriously tricky backpropagation algorithm.
At this stage, NNs were a sleeping giant. The potential was there, but it was locked away by complexity and cost.
Chapter 2: The Cambrian Explosion (2015-2017): A Tale of Two Frameworks
On November 9, 2015, Google open-sourced TensorFlow. A year later, in September 2016, PyTorch arrived. These frameworks shattered the barrier to entry, but they had different philosophies which set the stage for the next decade of innovation.
- TensorFlow was built for production. It introduced the concept of a static computation graph (a predefined model structure), which could be optimized and deployed at immense scale. This led to an entire ecosystem, TensorFlow Extended (TFX), for creating robust, enterprise-grade ML pipelines. Its focus was on stability, serving, and reliability.
- PyTorch was built for research. Its “define-by-run” or dynamic computation graph was revolutionary for builders. It behaved just like regular Python code, allowing for standard debugging and a more intuitive development process. It prioritized flexibility and ease of experimentation above all else.
If you were at this point in time, you could have made a critical prediction. You would have known that the next major leap in AI would come from a breakthrough in network architecture. And you would have guessed that this breakthrough was most likely to come from the community using the tool built for flexible, fast experimentation—the researchers and builders using PyTorch. The tool profoundly shapes the work.



Chapter 3: The Architectural Frontier (2017): The Birth of the Transformer
On June 12, 2017, the landmark paper “Attention Is All You Need” was published. It introduced the Transformer, an architecture that was vastly more effective for understanding context in language. This was the birth of the first true Large Language Models (LLMs).
If you were a builder at this moment, the next step was obvious. When a fundamentally new and powerful architecture like this appears—one that demonstrates a superior ability to handle sequences—the entire field pivots. The race is no longer about finding a new architecture, but about pushing this one to its absolute limits. The new research question became: “How far can the Transformer architecture scale?”
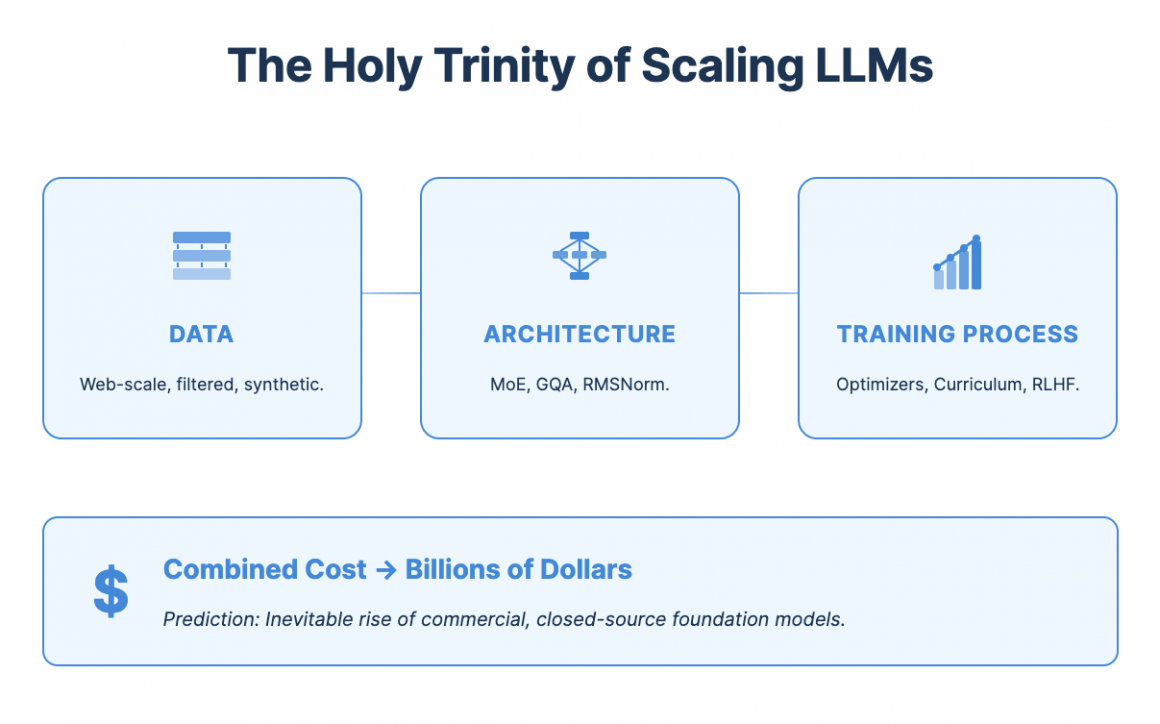
Chapter 4: The Scaling Race (2018-2022): The Holy Trinity of Growth
The obsession with scaling Transformers revealed that a model’s capability wasn’t governed by one or two factors, but by a “holy trinity” of three interconnected dimensions: Data, Architecture, and Training Process.
Dimension 1: Data
This was the most straightforward vector: more data leads to better performance. We moved from curated, high-quality datasets to scraping vast portions of the public internet. The challenge shifted from data collection to data filtering and curation at an unimaginable scale.
Dimension 2: Architecture
This is far more nuanced than simply “more layers and attention heads.” As we scaled up, the naive Transformer design hit engineering and performance walls. The architectural innovations were about scaling efficiently.
- Internal Connectivity: It’s not just the number of attention heads, but how they share information. Innovations like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) (techniques that allow multiple attention “heads” to share key computational resources) were introduced. This drastically reduces the memory bandwidth required during inference, making models faster and cheaper to run.
- Selective Activation: A massive model where every parameter is used for every token is computationally wasteful. This led to the rise of Mixture of Experts (MoE) layers (a design where only a fraction of the model’s “expert” sub-networks are used for any given input). This allows for a massive increase in a model’s parameter count (and thus its knowledge) without a proportional increase in the computing power (FLOPs) needed for each inference.
- Normalization and Positional Embeddings: Subtler but critical changes like switching to RMSNorm (Root Mean Square Normalization) for training stability or using novel RoPE (Rotary Positional Embeddings) to help the model understand word order in very long sequences were all crucial for enabling models to grow ever larger.
Dimension 3: Training Process
The architecture heavily influences the training process, but the process itself became a dimension of innovation. Having a brilliant architecture is useless if you can’t train it effectively. This involves the art and science of finding the right optimizer (like AdamW), learning rate schedule, and even data ordering (known as “curriculum learning”) to ensure the massive training run converges successfully.
At this point in time, you could have predicted the next phase of the industry with near-certainty. When scaling requires pushing the boundaries of data engineering, discovering novel architectural efficiencies, and fine-tuning an incredibly complex training process—all on thousands of GPUs for months—the cost explodes. This economic reality made the rise of well-funded, centralized labs like OpenAI, Google, and Anthropic the only logical outcome. The barrier to entry for training a state-of-the-art foundation model became capital.
Chapter 5: The Alignment Breakthrough (2022-2024): From Raw Power to Usability
For years, the most powerful LLMs were like wild, untamed engines—impressive but often unusable. The “ChatGPT Moment” on November 30, 2022, was not about raw intelligence, but about taming it.
This was an innovation in the Training Process dimension: Reinforcement Learning from Human Feedback (RLHF) (a method to align a model with human preferences). In essence, it involves training a separate “reward model” on human rankings of AI-generated answers, and then using that model to “reward” the LLM for producing outputs that a human would find helpful and safe. This process, along with more efficient successors like DPO (Direct Preference Optimization), is what made models steerable and genuinely useful.
With a model that was now safe and easy to talk to, you could easily predict what was next. The most obvious limitation of a text-only model is that our world is not text-only. The next frontier had to be expanding the model’s senses. This led directly to multimodality—creating a single model that could process text, images, and audio in a unified way. The release of GPT-4 with Vision and Google’s Gemini was not a surprise; it was the logical and necessary evolution from a usable chatbot to a more powerful reasoning engine.
Chapter 6: The Present is Agentic (2024-2025): From Thinkers to Doers
This brings us to today, and the shift that is already well underway. The predictions of the past have led us here. We now have powerful, multimodal models that can perceive and reason about the world. So, what is the logical application of a system that can perceive and reason? It is to act.
This is the Age of AI Agents. An agent is not a model; it’s a system built around an LLM core, turning a passive thinker into an active doer. The architecture of a basic agent consists of:
- The LLM Core (The “Brain”): The reasoning engine that makes decisions.
- Memory: Mechanisms for the agent to retain information, from short-term context to long-term vector databases.
- Planning: The ability to decompose a complex goal (e.g., “plan a trip to Hawaii”) into a sequence of smaller, manageable steps.
- Tools: Giving the model “hands” to interact with the world. This is the critical component that defines agency and includes:
- Retrieval-Augmented Generation (RAG): The ability to look up information in an external knowledge base before answering.
- Code Interpreter: The ability to write and execute code in a sandbox to perform calculations or analyze data.
- API Calls: The ability to interact with any external software via its API (e.g., to query a customer database or book a flight).
Frameworks like ReAct (Reason + Act) explicitly create an observation-thought-action loop, allowing the agent to pursue goals with a semblance of autonomy. The primary challenges we are working on right now in this agentic era are reliability, controllability, and specialization—turning generalist models into expert “AI employees.”
Conclusion: What Comes After Agents?
The AI landscape is not random. It’s a chain of cause and effect driven by engineering principles and economic realities. Understanding this allows you to see how the industry forked towards PyTorch for research, why costs drove the rise of commercial labs, and why agents are the undeniable present and near future of AI.
So, if agents that operate in the digital world are the present, what is the next logical step on this predictable path?
The clues lie where the digital world meets the physical. What happens when intelligence can not only access a calculator but can also pick up a tool? What new paradigms of computing will be required when our problems are no longer just about information, but about energy and matter?
That is the next grand frontier.
I’ll be sharing more of my thoughts on it soon. Follow me if you want to explore that future together.
Frequently Asked Questions
How can I keep up with AI without feeling overwhelmed?
Instead of chasing every new model release, focus on the underlying principles. Understand the core challenges the industry is trying to solve—such as scaling models efficiently, improving reasoning, or enabling action (agency). This framework allows you to see new breakthroughs as logical steps in a progression rather than random events.
What was the importance of the Transformer architecture?
The Transformer architecture, introduced in the 2017 paper “Attention Is All You Need,” was a fundamental breakthrough. It provided a vastly more effective way for models to handle sequential data and understand context, which became the foundational technology for modern Large Language Models (LLMs) like GPT.
What is the difference between a language model and an AI agent?
A language model is the core “brain” or reasoning engine that processes information and generates responses. An AI agent is a complete system built *around* a language model. An agent adds capabilities like memory, planning, and the ability to use tools (e.g., call APIs, run code, or access external data), allowing it to move from simply “thinking” to actively “doing.”
What drove the creation of large, centralized AI labs?
The “scaling race” from 2018-2022 created an economic and engineering moat. Training state-of-the-art models required pushing the limits of data collection, architectural innovation (like MoE and GQA), and complex training processes, all of which demanded massive capital investment in computing power (GPUs) and talent. This naturally favored the rise of large, well-funded organizations.

