
Key Takeaways
- Memory is Non-Negotiable: An agent without memory is not truly “agentic.” To move beyond simple stateless calculators, Agentic AI must be engineered with a robust memory system to learn, adapt, and personalize interactions.
- Two-Layer Cognitive Architecture: Production-grade Agentic AI mimics human cognition with two memory types: fast, volatile Short-Term Memory (STM) for immediate context (using Redis) and a persistent Long-Term Memory (LTM) for evolving knowledge.
- Hybrid Long-Term Memory is Key: A sophisticated LTM combines two powerful datastores: a Graph Database (like Neo4j) to understand complex relationships and facts, and a Vector Database (like Pinecone) for semantic or “fuzzy” search of past conversations.
- Implement Rigorous Guardrails: Before any data is stored, it must pass through an “Ingestion Gateway.” This involves crucial steps like PII redaction, toxicity filtering, fact extraction, and accuracy checks to prevent the agent from learning and spreading false or harmful information.
- Frameworks Accelerate Development: You can build a sophisticated memory architecture for Agentic AI using flexible toolkits like LangChain for modular components or managed cloud services like AWS (using ElastiCache, Neptune, and Bedrock) for a scalable, integrated path.
Infographics (save to remember):
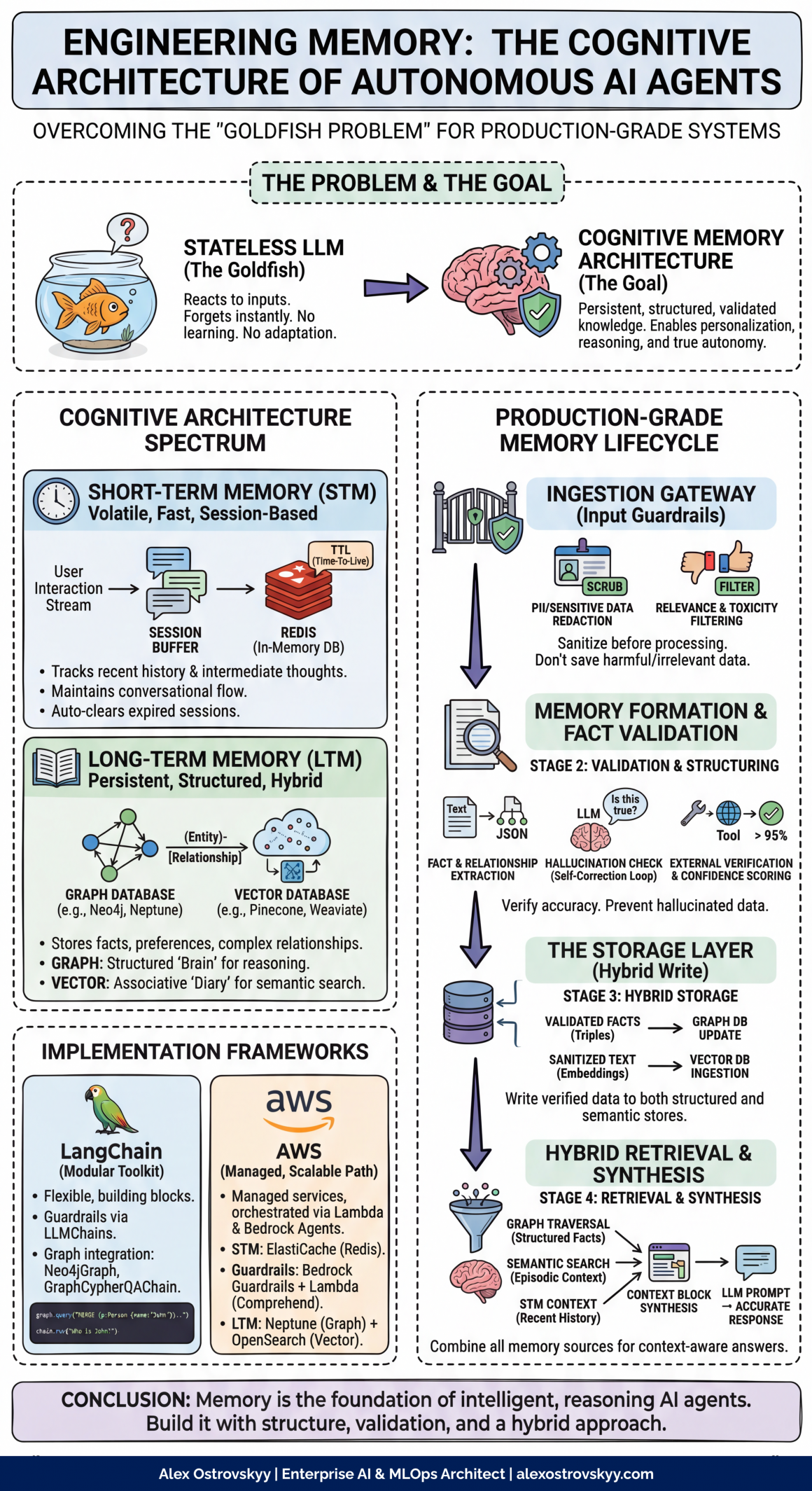
An intelligent agent that cannot remember is merely a sophisticated calculator, reacting to inputs but never truly learning or adapting. This is the core challenge with modern Large Language Models (LLMs)—they are inherently stateless, forgetting every interaction the moment it concludes. This “goldfish problem” is the single biggest barrier to creating truly autonomous, personalized, and effective Agentic AI.
To overcome this, we must engineer a memory system. This isn’t just a database, but a cognitive architecture with robust guardrails and a deep understanding of relationships. An AI with memory can move beyond simple Q&A to become a true partner that learns and reasons.
This article provides a comprehensive, production-grade guide to memory engineering for Agentic AI applications. We will explore the different types of memory, the multi-layered architecture of a secure and accurate memory system, and how to implement these systems using popular frameworks like LangChain and cloud services like AWS.
The Cognitive Architecture of Agentic AI Memory
Inspired by human cognition, the memory of an Agentic AI is not a single entity but a spectrum of systems. For a production-ready system, we must think beyond simple chat history and design a layered architecture that balances speed, depth, and accuracy.
Short-Term Memory (STM): The Agent’s Working Consciousness
Short-Term Memory (STM), also known as working memory, is the agent’s awareness of the immediate present. It is volatile, fast, and essential for maintaining conversational flow and executing multi-step tasks within a single session.
- Function: To track recent interactions, intermediate “thoughts,” and tool outputs. This prevents the agent from re-asking for information it just received.
- Datastore: Due to the need for high speed, an in-memory database like Redis is the industry standard. Redis allows for a Time-To-Live (TTL) on session data, ensuring memory from expired sessions is cleared automatically—a crucial practice for resource management and data hygiene.
- Implementation: In a production setting, a unique
session_idis assigned to each user session. All interactions are stored as a list or buffer under this key in Redis, providing a fast, scalable way to manage thousands of concurrent conversations.
Long-Term Memory (LTM): The Agent’s Evolving Knowledge Core
Long-Term Memory (LTM) allows an Agentic AI to persist and recall information across different sessions, enabling true personalization and learning. However, a production-grade LTM is not just a scrapbook of past conversations; it is a structured, verified knowledge base. For this, we must embrace a hybrid model.
- Function: To store and retrieve facts, user preferences, and complex relationships between entities learned over time.
- Datastore – A Hybrid Approach:
- Graph Database (e.g., Neo4j, Amazon Neptune): This forms the structured core of LTM. It stores information as nodes (entities like “User A”) and edges (relationships like “prefers”), allowing the agent to understand and query complex relationships with a depth that simple semantic search cannot match.
- Vector Database (e.g., Pinecone, Weaviate, Chroma): This serves as the agent’s associative or episodic memory. It stores embeddings of raw text from conversations, perfect for “fuzzy” searches based on semantic meaning or finding the original source of a memory.
This hybrid system gives the Agentic AI both a structured, queryable “brain” (the graph) and a searchable “diary” (the vector store).
The Production-Grade Memory Lifecycle
A robust memory system is a dynamic lifecycle involving sanitizing, structuring, storing, and retrieving information. This pipeline is essential for creating a reliable and safe Agentic AI.
Stage 1: The Ingestion Gateway (Input Guardrails)
Before any information is committed to memory, it must pass a strict validation gate. Storing incorrect data is worse than having no memory at all.
- Guardrail 1: PII and Sensitive Data Redaction: Never store personally identifiable information (PII) or credentials. Use a combination of rule-based methods (regex for API keys) and NLP services (like AWS Comprehend) to scrub or anonymize data.
- Guardrail 2: Relevance and Toxicity Filtering: Use a moderation model (like the OpenAI Moderation endpoint) to filter out toxic content. An LLM-based classifier can also determine relevance, ignoring simple greetings while flagging user preferences for storage.
Stage 2: Memory Formation and Fact Validation
Once cleared by the ingestion gateway, information must be structured and validated.
- Fact & Relationship Extraction: The sanitized information is passed to an LLM prompted to extract entities and relationships in a structured format (e.g., JSON triples).
- Guardrail 3: Hallucination & Accuracy Check: This is the most critical guardrail. Extracted “facts” must be verified.
- Self-Correction Loop: Use a second, independent LLM call to verify the extracted fact against the original source text.
- External Verification: For objective facts, the agent can trigger a tool (like a Google Search) to verify the information before committing it to the graph.
- Confidence Scoring: The LLM can assign a confidence score, and only facts above a predefined threshold (e.g., 95%) are stored.
Stage 3: The Storage Layer
Validated facts are now ready to be written into the hybrid storage system.
- Graph Database Update: The verified triple is written as nodes and an edge into the graph database (e.g., Neo4j).
- Vector Database Ingestion: The original, sanitized text snippet is converted into a vector embedding and stored in the vector database, with a metadata link back to the corresponding graph nodes.
Stage 4: Hybrid Retrieval and Synthesis
When the Agentic AI needs to recall information, it leverages its entire memory architecture.
- Entity Extraction from Query: The agent identifies key entities in the user’s current query.
- Parallel Retrieval: The agent performs two types of retrieval simultaneously:
- Graph Traversal: It queries the graph database for direct, factual answers.
- Semantic Search: It searches the vector database to find relevant past conversations, providing rich, episodic context.
- Synthesis: The retrieved information—structured facts from the graph, episodic context from the vector store, and the current conversation from STM—is compiled into a rich context block and injected into the LLM’s prompt. This allows the agent to generate a comprehensive, accurate, and context-aware response.
Implementation with Major Frameworks
You don’t have to build this entire system from scratch. Agentic AI frameworks and cloud platforms provide the necessary tools.
LangChain: The Flexible, Modular Toolkit
LangChain provides building blocks to construct this sophisticated memory architecture.
- Guardrails: Implement guardrails using
LLMChainsor simple Python functions. Libraries likepresidio-analyzercan be integrated for PII detection. - Graph Memory: LangChain has direct integration with graph databases like Neo4j. The
GraphCypherQAChainis specifically designed to take a natural language question, convert it to a Cypher query, execute it, and return a synthesized answer.
AWS: The Managed, Scalable Path
For production systems on AWS, you can compose several services orchestrated by an AWS Bedrock Agent.
- Short-Term Memory: Use Amazon ElastiCache (a managed Redis service) to store session data.
- Guardrails: Use native Bedrock Guardrails for content filtering and Custom Guardrails via AWS Lambda functions to call services like Amazon Comprehend for PII detection or to execute fact-checking loops.
- Long-Term Memory: A Lambda function can write verified data to Amazon Neptune (managed graph database) and Amazon OpenSearch Service (for vector search). When retrieving LTM, the Bedrock Agent calls the same Lambda function to query both datastores and return the synthesized context.
Conclusion: Building Agentic AI That Learns and Reasons
Memory is what elevates an AI from a simple tool to an intelligent partner. A production-grade memory system for an Agentic AI is far more than a chat log; it is a carefully architected lifecycle of ingestion, validation, structuring, and retrieval.
By implementing robust guardrails and a hybrid graph-and-vector database approach, we can build agents that not only remember but also understand the relationships within their accumulated knowledge. This advanced memory architecture is the true foundation for creating Agentic AI that is reliable, safe, and genuinely cognitive.
Frequently Asked Questions
What is Agentic AI?
Agentic AI refers to an artificial intelligence system that can act autonomously to achieve goals with limited human supervision. Unlike traditional AI, which requires step-by-step guidance, agentic systems can reason, plan, and adapt their actions based on their environment and past interactions.
Why is memory so important for Agentic AI?
Memory is the critical component that elevates a simple AI model into a truly intelligent and adaptive agent. Without it, an AI is stateless, forgetting every interaction instantly. A well-architected memory allows an Agentic AI to retain context, learn from experience, personalize responses, and understand complex relationships over time.
What is the difference between Short-Term and Long-Term Memory in an AI agent?
Short-Term Memory (STM) is the agent’s “working consciousness”—a fast, volatile memory (often using Redis) that tracks the immediate context of a single conversation. Long-Term Memory (LTM) is a persistent, structured knowledge base built over time. It combines graph databases for facts and vector databases for conversational history, allowing the agent to learn and evolve across many sessions.
What are “Guardrails” in the context of AI memory?
Guardrails are a series of validation and filtering steps that act as an “Ingestion Gateway” for the agent’s memory. Their purpose is to ensure data quality and safety by redacting sensitive information (PII), filtering out toxic or irrelevant content, and verifying the accuracy of facts before they are committed to the agent’s long-term memory.
How do frameworks like LangChain and AWS help build Agentic AI?
Frameworks provide the building blocks to construct a complex memory architecture more efficiently. LangChain offers a flexible, modular toolkit with direct integrations for graph databases and guardrail chains. AWS provides a managed, scalable path using services like Amazon ElastiCache for STM, Amazon Neptune for LTM (graph), and Amazon Bedrock Agents to orchestrate the entire workflow.

