
Let’s build our AI Agent with memory and tools.
Key Takeaways
- Go Beyond Stateless Agents: A standard AI Agent has no memory of past interactions, leading to a poor user experience. Adding a memory module allows the agent to hold context-aware, personalized conversations.
- Tiered Memory Architecture: This article proposes a two-tier memory system: fast, short-term memory (in-memory/RAM) for the current session and persistent, long-term memory (database) for user facts and conversation summaries.
- LangChain for Implementation: The solution uses LangChain’s `RunnableWithMessageHistory` to seamlessly manage conversational history and inject it into the agent’s context.
- Efficient Long-Term Storage: Instead of saving entire chat logs, the system summarizes conversations and extracts key user facts at the end of a session. This keeps the long-term memory concise and efficient, preventing context window overload.
- Combining Memory with Tools: The agent’s memory works in conjunction with its tools (e.g., SQL database for products, vector search for articles), allowing it to recall past requests and re-execute tasks to provide relevant information.
In one of the previous articles, we created a RAG agent that used tools to yield pretty interesting results (Production LLM: Agent with tools). It could solve multiple tasks quite well: finding products, finding articles, and performing math operations.
The problem with our previous Agent was that it had no memory whatsoever. Because of this reason, he answered any question as if this was a first message. And if I asked the RAG Agent, “Hey, what were those shoes again?” I would get no reply, which feels bad and is not the user experience we want our users to have.
Today, we will build the same Agent but with memory. So you would have a chance to see and feel the difference it makes and therefore its importance.
AI Agent with Memory
There could be different approaches to memory management, from simple message storing and adding the last n to the Agent context to much more sophisticated ones. Before we decide what our memory management system should look like, let’s talk more about memory itself.
In the memory, we usually store different types of information. We need at least these two types of data to be somehow persistent:
- Conversation history: this type contains the messages’ history and related information (requests, system messages, etc.).
- User history: in this vital memory section, we store everything we know about the user. This might not necessarily be every tiny bit of our knowledge of the user, but we usually try to capture most of it.
Each of the two types of data can also be divided into three tiers by the criteria of relevancy and importance:
- Tier 1: absolutely relevant, very important,
- Tier 2: relevant, somewhat important,
- Tier 3: could be important, could be relevant.
Relevant means how likely the information would be needed in every particular information. The most relevant bits of user data could be a user name or gender, for example. And for the conversation history, the most recent messages are often more relevant than the oldest ones.
When we combine these two classifications, we can define our best memory management approach for each of the combinations:
| Type | Tier 1 | Tier 2 | Tier 3 |
|---|---|---|---|
| Conversation | RAM | Database | Archival storage |
| User | RAM | RAM | Database |
As you can see in the table, we have to use three types of memory:
- Short-term memory, which our AI Agent with memory can access fast and frequently,
- Long-term memory, which our AI Agent can use when the information is not in the short-term memory,
- Archival memory is used for summarization and analysis.
When our AI Agent with memory talks to our user, short-term memory contains Tier 1 conversation history and Tier 1-2 used information; this way, our Agent will be equipped to answer most of the requests almost immediately.
If short-term memory is not enough, our Agent must be able to access long-term memory and look for anything helpful. One important point to consider is that long-term memory can contain information from many conversations and other sources, which is why it must be compacted or summarized.
This is why, at the end of every session (or conversation) with the user, we usually run a conversation summarization (or compactification) procedure, allowing short-term memory data to be moved and stored in the long-term memory.
And one more thing before I forget: there might also be sometimes a need to have a shared memory. This can be helpful when combining multiple Agents in a graph or organization. This can help Agents publish and access a shared pool of data to perform their tasks. They can also exchange thoughts and observations, publish messages, and more there.
Today, in our example, we will examine a simplified solution that uses only short—and long-term memory. In this solution, we will keep conversation history and user information (facts).
Let’s look at the code.
AI Agent with Tools
Like the last time, we will start by creating the tools that our AI Agent with memory would use.
When I work in colab, I like to add this bit below to make outputs more readable:
from IPython.display import HTML, display
def set_css():
display(HTML('''
<style>
pre {
white-space: pre-wrap;
}
</style>
'''))
get_ipython().events.register('pre_run_cell', set_css)Next, we install dependencies:
!pip install --quiet langchain-openai tiktoken langchain langchain-community langchain-experimental sqlalchemy-bigquery google-cloud-bigquery pinecone-clientAnd load credentials:
import json
import os
CHAT_GPT_API_KEY = <chat-gpt-api-key>
CHAT_GPT_ORG = <chat-gpt-organization>
model_name = 'gpt-4'
max_output_tokens = 1024
temperature = 0
BQ_SERVICE_ACCOUNT_CREDENTIALS = <service-account-credentials>
project_name = <project_name>
db_name = <db_name>
service_account_file = "credentials_bg.json"
if os.path.exists(service_account_file):
print('File is already there')
else:
with open(service_account_file, "w") as outfile:
outfile.write(json.dumps(BQ_SERVICE_ACCOUNT_CREDENTIALS))
PINECONE_API_KEY = <API key>
PINECONE_ENV = <pinecone-env>
index_name = <vectorstore-index-name>
Please keep in mind that the way credentials are initialized above is absolutely not the way to go in a demo or PoC application. I do it for this article to save your reading time (and, frankly, because I am lazy, and this is my weekend :)).
Next, we code the tool that would allow our AI Agent with memory to retrieve relevant products to recommend to our user:
from langchain.agents import create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.chat_models import ChatOpenAI as LangChainChatOpenAI
from langchain.agents.agent_types import AgentType
from langchain.prompts.prompt import PromptTemplate
def get_recommendation(query):
"""
Retrieves product recommendations based on a user query using a large language model
integrated with an SQL database.
Args:
query (str): The user query for which recommendations are to be made.
Returns:
str: The resulting recommendations processed by the language model.
"""
# Construct the path to the service account file, used for database authentication
path_to_sa_file = f'/content/{service_account_file}'
# Configure SQLAlchemy connection URL for BigQuery using service account credentials
sqlalchemy_url = f'bigquery://{project_name}/{db_name}?credentials_path={path_to_sa_file}'
# Initialize SQLDatabase using the connection URI
# Allows for execution of database queries and retrieval of product data
db = SQLDatabase.from_uri(sqlalchemy_url)
# Set parameters for the language model
max_output_tokens = 1024 # Maximum number of tokens that the model will return in response
temperature = 0.2 # Controls randomness in response (lower value = more deterministic)
top_p = 0.95 # Parameter for nucleus sampling, again controlling randomness
frequency_penalty = 1 # Penalizes new tokens based on their existing frequency
presence_penalty = 1 # Penalizes new tokens based on their presence in the response
# Initialize the language model with the above parameters, potentially from OpenAI's GPT architecture
get_recommendation_llm = LangChainChatOpenAI(
openai_api_key=CHAT_GPT_API_KEY,
openai_organization=CHAT_GPT_ORG,
model=model_name,
max_tokens=max_output_tokens,
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty
)
# Create SQL toolkit, associating the initialized database and language model
# This toolkit bridges database querying and language model processing
sql_toolkit = SQLDatabaseToolkit(db=db, llm=get_recommendation_llm)
# Establish the agent executor which runs queries using the LLM and SQL toolkit
agent_executor = create_sql_agent(
llm=get_recommendation_llm,
toolkit=sql_toolkit,
verbose=True,
max_iterations=20 # Allows the agent 20 iterations to refine its query or response
)
# Define the context or instructions for the agent on how to process the query and retrieve recommendations
context = '''
You are a helpful assistant who should recommend products for the user.
You will find the list of products in the dataset you were provided with.
You will find discount number in Discount column.
Listing Price column contains price of the product without discount.
Number of reviews are in the Reviews column.
When asked to recommend product, provide product name from Product Name column,
price from Sale Price column and rating from the Rating column of each product.
Based on Description column write a short description for each product you recommend.
Make it interesting and engaging.
If query returned no results try to relax the conditions and search for semantically
similar items or items of a wider/higher category.
Repeat search as many times as you need to return results. Each time use semantically
similar or wider search request terms.
'''
# Execute the query and context through the agent executor to get the recommendation results
result = agent_executor.run(context + query)
return resultRead more: Production LLM: SQL Agent.
And the tool that would allow our Agent to get a list of the relevant articles:
from langchain.chat_models import ChatOpenAI as LangChainChatOpenAI
from langchain.chains import RetrievalQA # Chain for retrieving and answering questions
from langchain_community.vectorstores import Pinecone as LangChainPinecone # Vector store access
from langchain_openai import OpenAIEmbeddings # For generating embeddings
import getpass # To handle password prompts if necessary
import os # For interacting with the operating system
def get_article(query):
"""
Retrieves a relevant article based on a user's query using a large language model
and a vector database for semantic searching.
Args:
query (str): The user query for which article recommendations are to be made.
Returns:
str: The resulting article link and description processed by the language model.
"""
# Set up environment variable for Pinecone API to enable vector store access
os.environ["PINECONE_API_KEY"] = PINECONE_API_KEY
# Configure parameters for language model operation
max_output_tokens = 1024 # Maximum tokens in the response
temperature = 0.2 # Controls randomness in generated responses; lower is more deterministic
top_p = 0.95 # Nucleus sampling parameter for randomness
frequency_penalty = 1 # Penalize repetitive phrases
presence_penalty = 1 # Penalize new tokens based on presence
# Initialize OpenAI embeddings for semantic similarity in text
embeddings = OpenAIEmbeddings(
api_key=CHAT_GPT_API_KEY,
organization=CHAT_GPT_ORG
)
# Instantiate a language model for generating responses relevant to articles
get_article_llm = LangChainChatOpenAI(
openai_api_key=CHAT_GPT_API_KEY,
openai_organization=CHAT_GPT_ORG,
model=model_name,
max_tokens=max_output_tokens,
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty
)
# Access a pre-existing vector database index to support semantic retrieval
doc_db = LangChainPinecone.from_existing_index(index_name=index_name, embedding=embeddings)
# Set up a RetrievalQA chain for query processing and answering using the language model and database
qa = RetrievalQA.from_chain_type(
llm=get_article_llm,
chain_type='stuff', # Placeholder for chain type definition
retriever=doc_db.as_retriever(search_type="mmr", search_kwargs={'k': 3, 'fetch_k': 5})
)
# Contextual instructions directing the query response generation to focus on blog articles
context = '''
You are a helpful assistant in the blog of Olex Ostrovskyy.
You can only answer questions about the materials of the blog.
Answer only based on the data you were provided with.
Provide Article link from the data you are provided with.
'''
# Combine the context with the user query and run through the QA chain to get result
result = qa.invoke(context + query)
# Return just the 'result' part of the response
return result['result']Read more: Production LLM: Vector Retriever.
Now we’ve created most of our tools, we can prepare them for our AI Agent:
from langchain_openai import ChatOpenAI as LangChainChatOpenAI
from langchain_core.tools import tool
@tool
def exponentiate(x: float, y: float) -> float:
"""Raise 'x' to the 'y'."""
return x**y
@tool
def add_func(x: float, y: float) -> float:
"""Deducts 'x' from 'y'."""
return x + y
@tool
def recommend_product(query: str) -> float:
"""Recommends products relevant for user request"""
return get_recommendation(query)
@tool
def recommend_article(query: str) -> float:
"""Recommends articles relevant for user request"""
return get_article(query)
Finally, everything is ready, and we can go ahead and create our AI Agent with memory and tools:
# Import necessary components from LangChain for creating agents and handling prompts
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import SQLChatMessageHistory
# Initialize a Large Language Model (LLM) using the LangChain's ChatOpenAI
# This model is configured to generate responses using OpenAI's API capabilities
llm = LangChainChatOpenAI(
openai_api_key=CHAT_GPT_API_KEY, # API key for authentication with OpenAI
openai_organization=CHAT_GPT_ORG, # Organization for managing related OpenAI accounts
model=model_name, # Specify the model to use, e.g., GPT-4
max_tokens=int(max_output_tokens), # Limit for the number of tokens in a response
temperature=float(temperature), # Temperature controls randomness; 0 is deterministic
)
# Define the system prompt which outlines the agent's behavior, limitations, and instructions
system_prompt = "You're a helpful assistant. Read the message history if you are being asked something about your previous answers."
# Create a structured prompt template that includes messaging types and history placeholders
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt), # Instruction for engaging with chat history
MessagesPlaceholder(variable_name="history"), # Placeholder for past conversation or message history
("human", "{input}"), # Capture human input into the conversation framework
("placeholder", "{agent_scratchpad}"), # Placeholder for agent processing or 'scratchpad' action
])
# List of tool functions that the agent can employ to perform specialized tasks
tools = [exponentiate, add_func, recommend_product, recommend_article]
# Initialize an agent using create_tool_calling_agent
# This sets up the agent with defined LLM, tools, and behavior prompts
agent = create_tool_calling_agent(
llm=llm, # Pass the configured LLM to the agent
tools=tools, # Tools that can be called by the agent for processing
prompt=prompt # The structured prompt guiding agent behavior and responses
)
# Setup the AgentExecutor, which manages the execution of the agent with access to specified tools
agent_executor = AgentExecutor(
agent=agent, # The initialized agent with processing logic
tools=tools, # Re-confirm the tool list available to the executor
verbose=False # Set verbosity; false limits debug or operational messages
)Read more: Production LLM: Agent with tools.
This is as far as we were when creating our Agent with tools. Now, we can start working with the memory.
AI Agent with Memory and Tools
As I mentioned before, our AI Agent with memory and tools will have two types of memory:
- short-term (stored in RAM),
- and long-term (stored in the database).
We will use a special wrapper from LangChain (RunnableWithMessageHistory) to make conversation memory available to the AI Agent.
An instance of RunnableWithMessageHistory, among other things, will manage two important operations:
- adding messages to the short-term memory,
- and getting and passing this data to our AI Agent.
from typing import List
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, AIMessage, SystemMessage, HumanMessage
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import ConfigurableFieldSpec
# Global dictionary to maintain chat histories
chat_store = {}
class InMemoryHistory(BaseChatMessageHistory, BaseModel):
"""In-memory implementation of chat message history, intended for storing a conversation's messages."""
# List of message objects stored using Pydantic's Field for default initialization
messages: List[BaseMessage] = Field(default_factory=list)
def add_messages(self, messages: List[BaseMessage]) -> None:
"""
Add a list of messages to the current message history.
Args:
messages (List[BaseMessage]): List of messages to be added to the history.
"""
# Extend the current messages with the new list of messages provided
self.messages.extend(messages)
def clear(self) -> None:
"""Clear the message history, removing all stored messages."""
self.messages = [] # Resets the messages list to empty
# Pydantic model configuration to allow inclusion of arbitrary types in the field
class Config:
arbitrary_types_allowed = True
def get_session_history(user_id: str, conversation_id: str) -> BaseChatMessageHistory:
"""
Retrieve or initialize a conversation history session for a specific user and conversation identifiers.
Args:
user_id (str): Identifier for the user.
conversation_id (str): Identifier for the conversation session.
Returns:
BaseChatMessageHistory: The message history tied to the specified user and conversation session.
"""
# If no history exists for the specified user and conversation pair, create a new history instance
if (user_id, conversation_id) not in chat_store:
chat_store[(user_id, conversation_id)] = InMemoryHistory()
# Initialize by copying messages from a default or zeroth session where we add any long-term data about our user
chat_store[(user_id, conversation_id)].add_messages(chat_store.get((user_id, '0'), {}).get("messages", []))
# Return the relevant message history object from the chat_store
return chat_store[(user_id, conversation_id)]
# Define an agent with capability to store and recall message history, allowing interaction context preservation
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor, # The main agent executor that processes queries
get_session_history=get_session_history, # Method to retrieve session history
input_messages_key="input", # Key name to identify input in the messages
output_messages_key="output", # Key name to identify output in the messages
history_messages_key="history", # Key name for storing message history
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="User ID",
description="Unique identifier for the user.", # Describes the usage of the User ID
default="", # Default value if none is provided
is_shared=True, # Indicates that the User ID can be shared across different components
),
ConfigurableFieldSpec(
id="conversation_id",
annotation=str,
name="Conversation ID",
description="Unique identifier for the conversation.", # Describes the usage of the Conversation ID
default="", # Default value if none is provided
is_shared=True, # Indicates that the Conversation ID is a shared parameter
),
],
)This was not too difficult, right? As we are building a custom short-term management component, you can extend the logic as you would like.
The one thing we have left to figure out is how to properly transfer our short-term memory into long-term memory. We could have just saved everything to the database and called it a day, but we would face a problem in such a case. And that problem is the size: potentially, our users could have any conversations with our AI Agent with memory. When this is all stored in the raw form, it would not fit into the context window or make the task much more computationally expensive and longer than necessary.
To solve this problem, we will update our AI Agent’s knowledge about the user and summarize the conversation. We would store facts about our users and a list of summarized conversations. This would be much more efficient.
Let’s create a few helper methods that we will use at the beginning and the end of the session:
import sqlite3 # SQLite3 library for database operations
from contextlib import closing # Utility for resource management
import datetime # Library to handle date and time
from langchain.chat_models import ChatOpenAI as LangChainChatOpenAI # Import OpenAI LLM from LangChain
# Function to initialize the SQLite database with necessary tables
def initialize_db():
# Establish a connection to the chatbot SQLite database, with a connection time-out
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
# Ensure tables exist for storing user personas and message logs
cursor.execute("CREATE TABLE if not exists personas (id INTEGER, facts TEXT)")
cursor.execute("CREATE TABLE if not exists messages (id INTEGER, date datetime default current_timestamp, content TEXT)")
connection.commit() # Commit the changes to the database
cursor.close() # Close the cursor object
connection.close() # Ensure the connection is properly closed to avoid leaks
# Function to clear all entries from tables in the database
def clear_db():
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
# Delete all rows from personas and messages tables
cursor.execute("DELETE FROM personas")
cursor.execute("DELETE FROM messages")
connection.commit() # Save the cleanup to the database
cursor.close()
connection.close()
# Function to load conversation summaries for a specific user
def load_conversation_summaries(user_id: int, n: int):
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
# Fetch 'n' conversation summaries for the given user_id from the messages table
rows = cursor.execute("SELECT * FROM messages WHERE id = ? LIMIT ?", (user_id, n)).fetchall()
cursor.close()
connection.close()
return rows # Return the retrieved rows
# Function to load user facts from the database
def load_user_facts(user_id: int):
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
# Get facts associated with a specific user_id from the personas table
rows = cursor.execute("SELECT * FROM personas WHERE id = ?", (user_id,)).fetchall()
cursor.close()
connection.close()
return rows # Return the retrieved facts
# Function to summarize a conversation using an LLM model
def summarize_conversation(user_id: int, incoming_messages: List):
# Initialize the LLM for summarization using OpenAI's API
summarization_llm = LangChainChatOpenAI(
openai_api_key=CHAT_GPT_API_KEY,
openai_organization=CHAT_GPT_ORG,
model=model_name,
max_tokens=int(max_output_tokens),
temperature=float(temperature),
)
# Construct the system message instructing how to create a summary
messages = [
(
"system",
"Summarize the conversation so that you can recall what had happened if user asks "
"you in future or refers to the previous conversations. Keep it brief, but also try "
"to keep as much factual and important information about human and conversation as possible.",
),
]
messages.extend(incoming_messages) # Append incoming messages to the summary
results = summarization_llm.invoke(messages) # Generate summary results
# Save the summary to the messages table in the database
with sqlite3.connect("chatbot.db", timeout=10.0) as message_connection:
message_cursor = message_connection.cursor()
conversation_summary = f"<conversation>{results.content}</conversation>"
message_cursor.execute("INSERT INTO messages VALUES (?, ?, ?)", (user_id, datetime.datetime.now(), conversation_summary))
message_connection.commit()
# Function to update user's facts based on the latest conversation
def update_user_facts_from_conversation(user_id: int, incoming_messages: List):
with sqlite3.connect("chatbot.db", timeout=10.0) as user_connection:
user_cursor = user_connection.cursor()
# Fetch user facts from the personas table
rows = user_cursor.execute("SELECT * FROM personas WHERE id = ?", (user_id,)).fetchall()
if rows:
has_profile = True
user_facts = rows[0]
user_facts = f'The known facts about user are following: {user_facts}. '
else:
has_profile = False
user_facts = 'You have no prior information about user. '
# Analyze and synchronize facts using LLM
summarization_llm = LangChainChatOpenAI(
openai_api_key=CHAT_GPT_API_KEY,
openai_organization=CHAT_GPT_ORG,
model=model_name,
max_tokens=int(max_output_tokens),
temperature=float(temperature),
)
context = f'''
{user_facts}
You need to analyze the conversation to see if any new facts about the user can be added, old facts should be removed or updated.
You are only looking for facts about user and their preferences, not what user have done or said.
You need to analyze all facts. When two facts conflict each other, you need to exclude one that was discovered earlier.
The ones that were discovered earlier are the first you will read.
Update facts about user and provide a cohesive set of facts about user.
Which means that you have to exclude earlier facts that are conflicting with the later facts.
Each fact has to be enclosed in <fact> tags, like <fact>User name is Olex</fact>.
'''
messages = [("system", context, )]
messages.extend(incoming_messages)
results = summarization_llm.invoke(messages)
# Update or insert the updated user facts to the personas table in the database
upd_persona = results.content
if has_profile:
user_cursor.execute("UPDATE personas SET facts = ? WHERE id = ?", (upd_persona, user_id))
else:
user_cursor.execute("INSERT INTO personas VALUES (?, ?)", (user_id, upd_persona))
user_connection.commit()Great, now we can initialize our database:
initialize_db()And check if it is empty:
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
rows = cursor.execute(f"SELECT * FROM personas WHERE id = ?", (user_id,)).fetchall()
print('\n Persona Rows: \n', rows)
rows = cursor.execute(f"SELECT * FROM messages").fetchall()
print('\n Messages Rows: \n', rows)
cursor.close()
connection.close()Let’s test our solution.
Testing AI Agent with Memory and Tools
We will test two scenarios:
- Cold initialization: There is no information about the user. The AI Agent talks to the user. At the end of the session, we summarize what the AI Agent knows about the user and summarize the conversation to store both in long-term memory.
- Warm initialization: At the initialization, we found out that this user was familiar with our AI Agent. We would retrieve the information, and the AI Agent will use memory to understand user requests better.
The initialization is going to be universal and the same across both of the scenarios.
AI Agent with Memory and Tools Cold Initialization
Lets launch initialization:
# Step 1: Initialize a Global Dictionary to Track Chat Histories
chat_store = {} # Clear store message histories
# Step 2: Define the user and conversation IDs
user_id = 123 # Identifier for the current user interacting with the system
conversation_id = "1" # Identifier for the specific conversation session
# Step 3: Load Previous Conversations and User Facts
# Call functions to retrieve recent conversation summaries and known user facts from a database or storage
conversation_history_data = load_conversation_summaries(user_id, 3) # Load last 3 conversation summaries for the user
user_facts_data = load_user_facts(user_id) # Load stored facts about the user
# Step 4: Process and Construct the Conversation History
if conversation_history_data:
# If there is existing conversation history, format it into a user-facing summary
print('conversation_history_data', conversation_history_data) # Debug output to verify loaded history
conversation_history = f'Summary of previous conversations with the user: \n {str(conversation_history_data)} \n'
else:
# If no prior history exists, prepare a default message indicating no previous interactions
conversation_history = (
'This is the first conversation with this user. '
'You should not say that you have no memory. If the user asks if you remember them, '
'just say that according to your memory this is the first time you speak. \n'
)
# Step 5: Process and Compile User Facts
if user_facts_data:
# If facts about the user exist, format them into a comprehensive summary
user_facts = f'This is what you know about the user: \n {user_facts_data} \n'
else:
# If no user facts are available, set description as an empty string
user_facts = ''
# Step 6: Launch the Chat Session with Compiled Data
# Construct an entry in the chat history store for the current session associated with the user
chat_store[(user_id, '0')] = { # '0' may signify a default or starting session for the user
"messages": [
SystemMessage(
content=user_facts + conversation_history # Combine user facts and conversation history into a single message
),
]
}As we know, the AI Agent has no prior information about the user, so we can go ahead and start asking questions.
We can start with the same question we asked our AI Agent with memory and tools:
result = agent_with_chat_history.invoke(
{"input": "I need shoes for hiking with good discount. Do you have any articles about LLMs? Also, what's 3 plus 5 raised to the 2.743?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])The output for me looks like the following:



Let’s check if the information is now stored in the short-term memory:
result = agent_with_chat_history.invoke(
{"input": "What did I just ask you?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])
Then we ask another question about shoes. I am doing this because I want to test later how well we designed the procedure of transferring information from short-term to long-term storage.
result = agent_with_chat_history.invoke(
{"input": "I need premium shoes for sport"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])The output for me looks like the following:

Next, I want to give updated facts about myself to test how this can be stored in both short-term and long-term memory and used by the AI Agent.
result = agent_with_chat_history.invoke(
{"input": "Please call me mister Bob from now on"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])
Next, we can test how well our AI Agent with memory and tools can navigate conversational memory. We can ask a question about shoes we were asking about before, and our Agent should understand that we are likely interested in the last shoe-related question rather than the previous one.
result = agent_with_chat_history.invoke(
{"input": "What were the shoes again?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])
Ok, it seems that our AI Agent can use the short-term memory correctly.
We can transfer the conversation to long-term memory by:
- summarizing the conversation, adding a new entry with conversation summary,
- and updating user facts entries in the corresponding tables.
summarize_conversation(user_id, chat_store[(user_id, conversation_id)].messages)
update_user_facts_from_conversation(user_id, chat_store[(user_id, conversation_id)].messages)Let’s check the entries:
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
rows = cursor.execute(f"SELECT * FROM personas WHERE id = ?", (user_id,)).fetchall()
print('\n Persona Rows: \n', rows)
rows = cursor.execute(f"SELECT * FROM messages").fetchall()
print('\n Messages Rows: \n', rows)
cursor.close()
connection.close()
The AI Agent got all the relevant facts about the user persona and summarized the conversation quite well.
Next, we can test long-term memory retrieval and use.
AI Agent with Memory and Tools Warm Initialization
After our previous conversation, facts and history were stored in our database. The data will become part of the AI Agent context during the next initialization (the code is the same as before).
We do this by adding the system message during initialization. The LLM (GPT-4 in this example) is usually smart enough to use the latest data from the conversation history if the initial system message conflicts with something the AI Agent later discovered. This is why we use the initial system message to pass the long-term memory data to the AI Agent.
In production systems, we usually add the ability to interact with long-term memory, not just at the initialization. Our AI Agent should be able to retrieve knowledge from long-term and even archive storage during the conversation.
But here, for simplicity, we add long-term memory only at the initialization phase.
# Step 1: Initialize a Global Dictionary to Track Chat Histories
chat_store = {} # Clear store message histories
# Step 2: Define the user and conversation IDs
user_id = 123 # Identifier for the current user interacting with the system
conversation_id = "1" # Identifier for the specific conversation session
# Step 3: Load Previous Conversations and User Facts
# Call functions to retrieve recent conversation summaries and known user facts from a database or storage
conversation_history_data = load_conversation_summaries(user_id, 3) # Load last 3 conversation summaries for the user
user_facts_data = load_user_facts(user_id) # Load stored facts about the user
# Step 4: Process and Construct the Conversation History
if conversation_history_data:
# If there is existing conversation history, format it into a user-facing summary
conversation_history = f'Summary of previous conversations with the user: \n {str(conversation_history_data)} \n'
else:
# If no prior history exists, prepare a default message indicating no previous interactions
conversation_history = (
'This is the first conversation with this user. '
'You should not say that you have no memory. If the user asks if you remember them, '
'just say that according to your memory this is the first time you speak. \n'
)
# Step 5: Process and Compile User Facts
if user_facts_data:
# If facts about the user exist, format them into a comprehensive summary
user_facts = f'This is what you know about the user: \n {user_facts_data} \n'
else:
# If no user facts are available, set description as an empty string
user_facts = ''
# Step 6: Launch the Chat Session with Compiled Data
# Construct an entry in the chat history store for the current session associated with the user
chat_store[(user_id, '0')] = { # '0' may signify a default or starting session for the user
"messages": [
SystemMessage(
content=user_facts + conversation_history # Combine user facts and conversation history into a single message
),
]
}We can check the entries again:
connection = sqlite3.connect("chatbot.db", timeout=10.0)
cursor = connection.cursor()
rows = cursor.execute(f"SELECT * FROM personas WHERE id = ?", (user_id,)).fetchall()
print('\n Persona Rows: \n', rows)
rows = cursor.execute(f"SELECT * FROM messages").fetchall()
print('\n Messages Rows: \n', rows)
cursor.close()
connection.close()
And start testing with the simple question:
result = agent_with_chat_history.invoke(
{"input": "Hey, do you remember me?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])
Let’s ask something a bit more complicated:
result = agent_with_chat_history.invoke(
{"input": "What were the shoes I asked you last time?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])
That’s not too bad. But as you know, because of the summarization process, our AI Agent with memory does not have a specific set of products in its memory.
We can try to put it in a difficult situation with our next question:
result = agent_with_chat_history.invoke(
{"input": "Can you send me the list again?"},
config={"configurable": {"user_id": user_id, "conversation_id": conversation_id}}
)
print('\n', result['output'])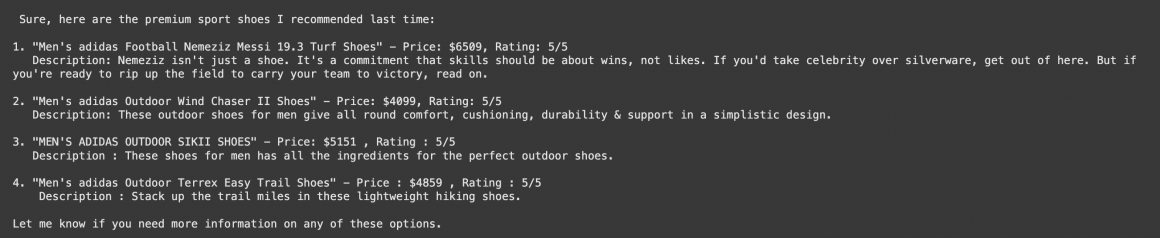
Impressive, isn’t it? Our AI Agent was able to use history and tools to retrieve the information needed. As long as the state of data in the database remains the same, the answer from before should match.
Please go ahead and play more with the Agent. I found that the experience I am getting is not too bad at all, especially compared to working with an Agent without memory.
Conclusion
Today, we discussed memory management for AI Agent with memory and tools. Using the tools from the previous article, we created a memory wrapper for our Agent, which allowed us to persist short-term memory into long-term memory and use it efficiently.
This opens a new world of possibilities for us going forward:
- The AI Agents with memory are not just consumers of the user information. They are actively sourcing and refining this information.
- Once information is persistent, it can be analyzed and shared. Analysis of the cleaned and refined information about user and bot interactions with users would open many possibilities for product and user experience improvements.
- The persistent knowledge can now be shared, consumed, and enhanced by many AI Agents in real-time.
The last bit is especially very interesting because it opens up the possibility of building a network of AI Agents (sometimes called an organization of AI Agents).
AI Agents in such networks can have specialization and tools to perform their duties. However, they all can be connected to a shared pool of knowledge that they can use and enhance to perform their duties.
That also includes communication in such an organization and the ability to brainstorm and discuss.
This sounds exciting, doesn’t it? In the following articles, I will show how such a network (or organization) can be built using AI Agents, tools, and memory management. Stay tuned!
Frequently Asked Questions
Why is memory important for an LLM agent?
Memory allows an LLM agent to recall past interactions within the same conversation and across different sessions. This is crucial for providing a human-like, context-aware experience. A stateless agent treats every query as its first, while an agent with memory can understand follow-up questions, remember user preferences, and build a more personalized and effective dialogue.
What is the difference between short-term and long-term memory in this AI agent?
Short-term memory is used for the current conversation and is stored in RAM for quick access. It holds the immediate back-and-forth dialogue. Long-term memory is persistent and stored in a database (like SQLite in this example). It holds summaries of past conversations and key facts learned about the user, allowing the agent to remember the user across multiple sessions.
How does the agent prevent its memory from becoming too large for the context window?
To manage the size of its long-term memory, the agent doesn’t store the entire raw transcript of every conversation. Instead, at the end of a session, it runs a summarization process. This process creates a concise summary of the conversation and extracts or updates key facts about the user. This compact data is then stored, ensuring the context provided to the agent remains manageable and efficient.
What role does LangChain play in building this agent?
LangChain provides the core framework for this architecture. Specifically, it offers the `create_tool_calling_agent` to build the agent, `AgentExecutor` to run it, and, most importantly, the `RunnableWithMessageHistory` wrapper. This wrapper simplifies the process of saving, retrieving, and injecting conversation history into the agent’s prompt.

